Finetuned Language Models Are Zero-Shot Learners
Finetuned Language Models Are Zero-Shot Learners
This paper explores a simple method for improving the zero-shot learning abilities of language models. We show that instruction tuning -- finetuning language models on a collection of tasks described via instructions -- substantially improves zero-shot per
arxiv.org
- <논문 리뷰 목차>
- 제안 모델: FLAN
- 배경
- 선행 모델의 문제점
- 제안 모델: 선행 문제 해결방안
- 제안모델: FLAN, 아이디어, 평가방법 등등
- 평가 결과 분석
- 논문의 기여점 및 한계점
- 기여점
- 한계점
[Abstract]
제안 모델: FLAN
본 논문에서는 언어 모델의 제로샷 학습 능력을 향상시키기 위한 간단한 방법을 탐구
-
- instruction tuning: 즉 여러 데이터셋을 설명하는 지침(instructions)을 사용하여 언어 모델을 미세 조정(finetuning)하는 것 → 제로샷 성능을 향상 시킴을 보여줌
- fine-tuning + prompt-tuning = instruction tuning
- 1370억 개의 파라미터를 가진 사전 학습된 언어 모델을 가져와 60개 이상의 자연어 처리(NLP) 데이터셋에서 자연어 instruction템플릿을 사용해 인스트럭션 튜닝을 수행 ⇒ FLAN 제안

- instruction tuning: 즉 여러 데이터셋을 설명하는 지침(instructions)을 사용하여 언어 모델을 미세 조정(finetuning)하는 것 → 제로샷 성능을 향상 시킴을 보여줌
[1. 배경]
1) 선행 모델의 문제점
- GPT3와 같이 LLM은 few-shot에 뛰어난 성능을 보이지만, 여전히 zero-shot에는 덜 발전되었다.
- 그 이유는 few-shot 예시 없이는 학습데이터와 비슷하지 않은 형태의 프롬프트에서 좋은 성능을 보이기 더 어렵기 때문이다.
2) 제안 모델: 선행 문제 해결방안
- 사전학습된 모델을 instruction tuning하여 zero-shot 성능을 개선
- 처음 접하는 task에서도 좋은 zero-shot 성능을 보이기 위해,
- NLP 데이터셋을 작업 유형에 따라 클러스터로 그룹화하고
- 각 클러스터를 평가용으로 보류하는 동안 FLAN을 다른 모든 클러스터에서 인스트럭션 튜닝한다
- ex) FLAN의 자연어 추론 성능을 평가하기 위해, 상식 추론, 번역, 감정 분석과 같은 다양한 다른 NLP 작업에서 모델을 instruction tuning 진행 → FLAN이 instruction tuning 과정에서 자연어 추론 작업을 전혀 보지 않았음을 보장하며, 이후 모델의 제로샷 자연어 추론 능력을 평가

[2. 제안 모델: FLAN, 아이디어, 평가방법 등등]
- instruction tuning의 동기: 언어 모델이 NLP 지시에 반응하는 능력을 향상시키는 것
- 메인 아이디어: 인스트럭션을 통해 작업을 수행하도록 언어 모델을 지도 학습하면, 언어 모델이 지시에 없는 처음 접하는 작업에 대해서도 지시를 따를 수 있게 될 것이라는 아이디어
- 평가 방법(unseen Task): 처음 접하는 task에서도 좋은 zero-shot 성능을 보이기 위해,
Task A를 추론하고 싶은 경우, Task A를 제외한 Task에서 학습 후 Task A에서 zero-shot 성능 평가 진행 - 템플릿(데이터셋) 구성
1. NLP 데이터셋을 작업 유형에 따라 클러스터로 그룹화- 작업 유형 분리: 각 데이터셋은 12개의 작업 클러스터 중 하나로 분류되며, 주어진 클러스터의 데이터셋들은 동일한 작업 유형에 속함
- Instruction을 통한 템플릿 생성: 각 데이터셋에 대해, 해당 데이터셋의 작업을 설명하는 자연어 지시문을 사용하여 10개의 고유한 템플릿을 수작업으로 작성
- 데이터셋 다양성 증진: 각 데이터셋에 대해 작업을 "뒤집는" 최대 세 개의 템플릿도 포함
- 예를 들어, 감정 분류 작업의 경우, 영화 리뷰를 생성하라는 요청을 포함한 템플릿을 추가
- 작업 유형 분리: 각 데이터셋은 12개의 작업 클러스터 중 하나로 분류되며, 주어진 클러스터의 데이터셋들은 동일한 작업 유형에 속함
2. 모든 데이터셋의 혼합물에 대해 사전 학습된 언어 모델을 인스트럭션 튜닝하며, 각 데이터셋의 예제는 해당 데이터셋에 대해 무작위로 선택된 지시문 템플릿으로 포맷
- 해당 task의 출력결과: (classification) or free text (generation)
- 디코더 전용 언어 모델(LaMDA-PT: 137B param)의 인스트럭션 튜닝 버전이기 때문에, 자연스럽게 free text로 응답하며 생성 작업을 위해 추가적인 수정이 필요
- (LaMDA-PT 한계) 데이터셋의 크기가 다 다름 → (해결방안) T5에서 고안한 Examples-proportional mixing scheme을 통해 크기가 큰 데이터셋을 편향되게 샘플링하는 문제점 해결
[3. 평가 결과 분석]
작업에 따른 결과:
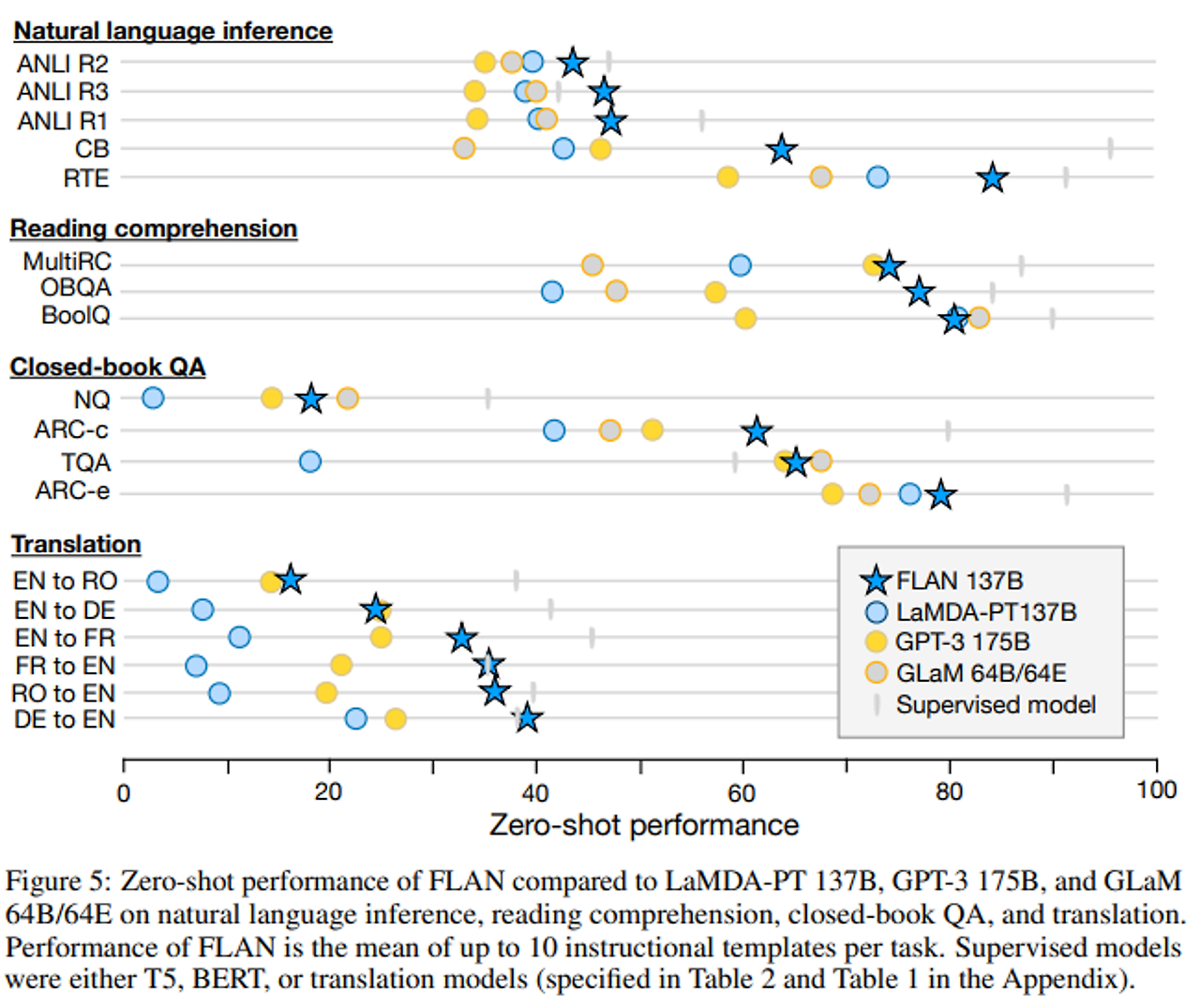
- 자연어 추론 (NLI): 모델이 주어진 전제를 바탕으로 가설이 참인지 결정
- FLAN은 NLI 데이터셋에서 모든 기준 모델을 큰 차이로 초월.
- FLAN은 "Does <premise> mean that <hypothesis>?" 형식의 자연스러운 질문으로 NLI를 표현하여 높은 성능 달성.
- 독해: 주어진 글에 대해 질문에 답하는 독해 과제
- MultiRC와 OBQA에서 FLAN은 기준 모델들보다 성능 우수.
- BoolQ에서는 FLAN이 GPT-3를 크게 능가하지만, LaMDA-PT도 이미 높은 성능을 기록.
- Closed-book QA: 답을 포함하는 특정 정보에 접근하지 않고 세계에 대한 질문에 답하는
- FLAN은 네 개의 데이터셋에서 GPT-3를 능가.
- GLaM과 비교 시, FLAN은 ARC-e와 ARC-c에서 더 나은 성능, NQ와 TQA에서는 약간 낮은 성능.
- 번역:
- FLAN은 GPT-3의 제로샷 성능을 모든 여섯 개 번역 평가에서 초과.
- 퓨샷 GPT-3에는 대부분의 경우 낮은 성능을 보였으나, 영어로 번역하는 데 강력한 결과를 보임.
- 영어에서 다른 언어로의 번역은 상대적으로 약하며, 이는 FLAN의 영어 중심 사전 학습 데이터와 관련됨.
[NUMBER OF INSTRUCTION TUNING CLUSTER]
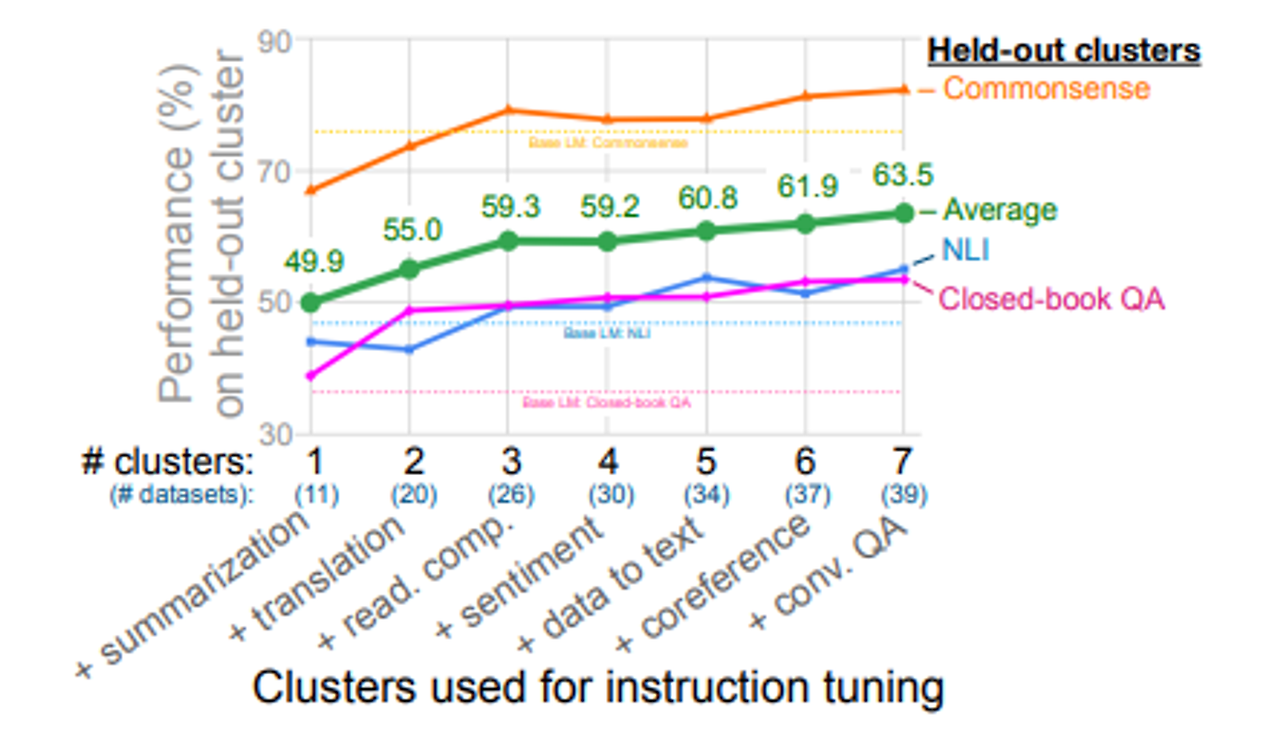
- 성능 향상: instruction tuning에 클러스터(데이터셋 크기)와 작업을 추가함에 따라 개선됨
- 성능 추가 개선 가능성 존재: 테스트한 7개의 클러스터에서 성능이 포화되지 않는 것으로 보이며, 추가 클러스터가 추가될 경우 성능이 더 개선될 수 있음을 시사
- 클러스터 기여도: 이 분석에서는 각 instruction tuning 클러스터가 평가 클러스터에 기여하는 정도를 명확히 파악할 수 없지만, 감정 분석 클러스터의 추가 효과는 미미한 것으로 보임
[SCALING LAWS] : 모델의 규모와 Instruction Tuning의 효과
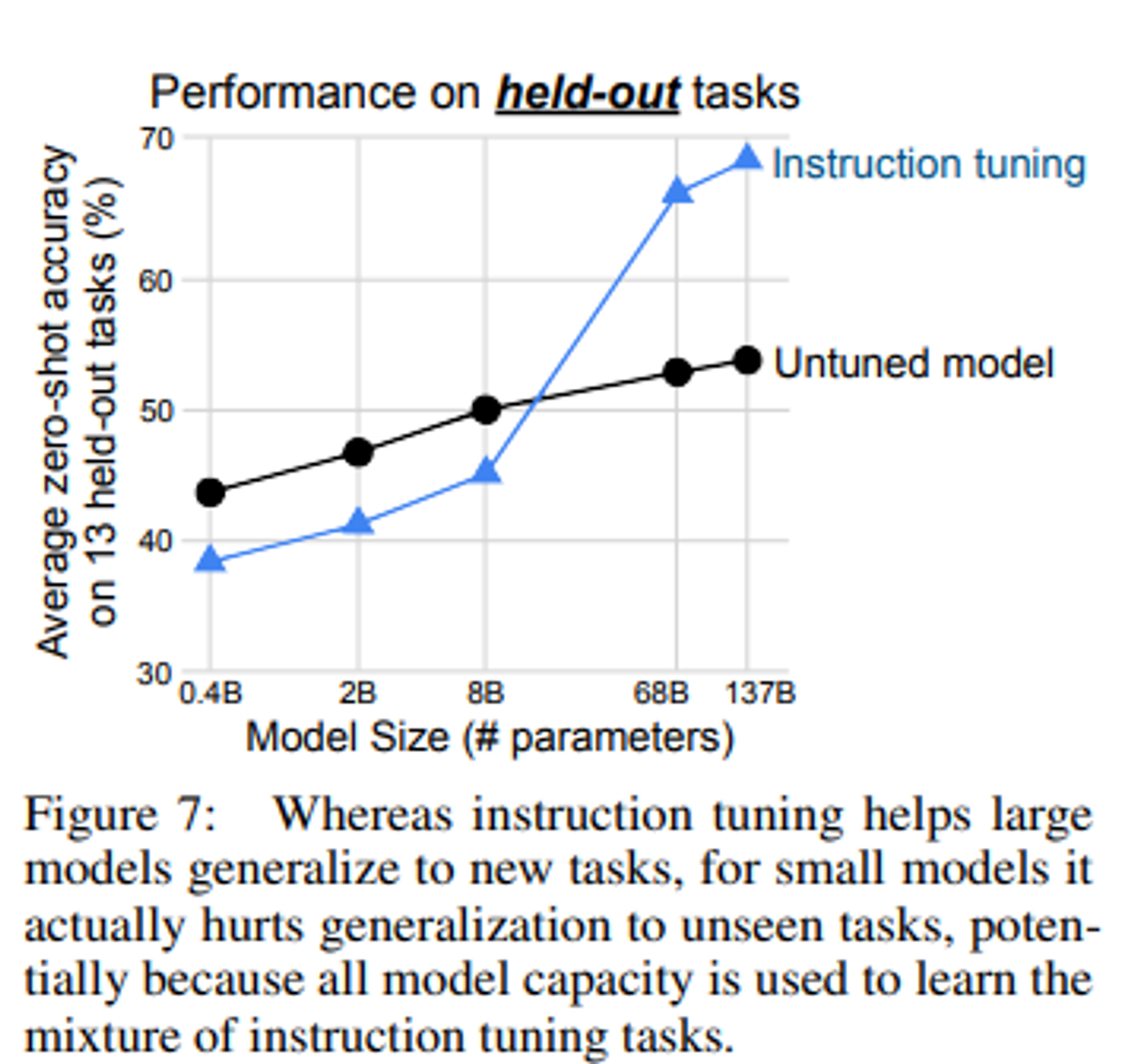
- 큰 모델은 instruction tuning을 통해 모델 용량을 일부 채우면서도 명령을 따르는 방법을 학습하여 새로운 작업에 대한 일반화가 가능
- 작은 모델은 용량이 가득 차서 새로운 작업에서 성능이 저하될 수 있다.
[instruction tuning의 역할] : 무엇이 성능을 향상시켰을까? instruction-tuning or 추가 학습
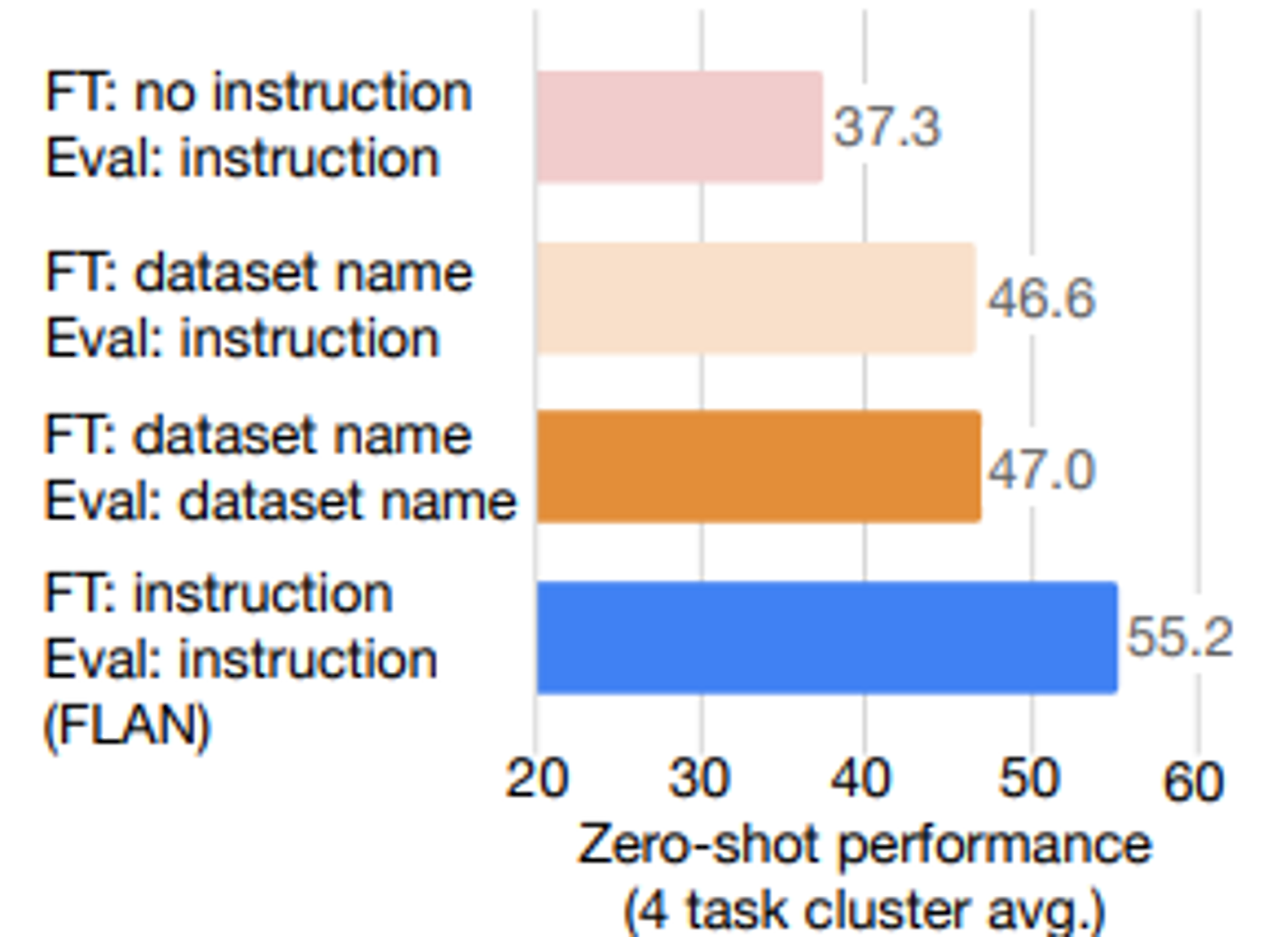
- 두 가지 instruction 없는 fine-tuning 설정을 고려
- No Template Setup
- Dataset Name Setup: 각 입력에 작업과 데이터셋 이름이 앞에 붙음
- 두 ablation 구성 모두 FLAN보다 성능이 훨씬 떨어졌으며, 이는 instruction으로 학습하는 것이 unseen tasks에서의 zero-shot 성능에 중요하다는 것을 나타냅니다.
[few-shot 예제가 추론 시에 어떻게 활용될 수 있는지]
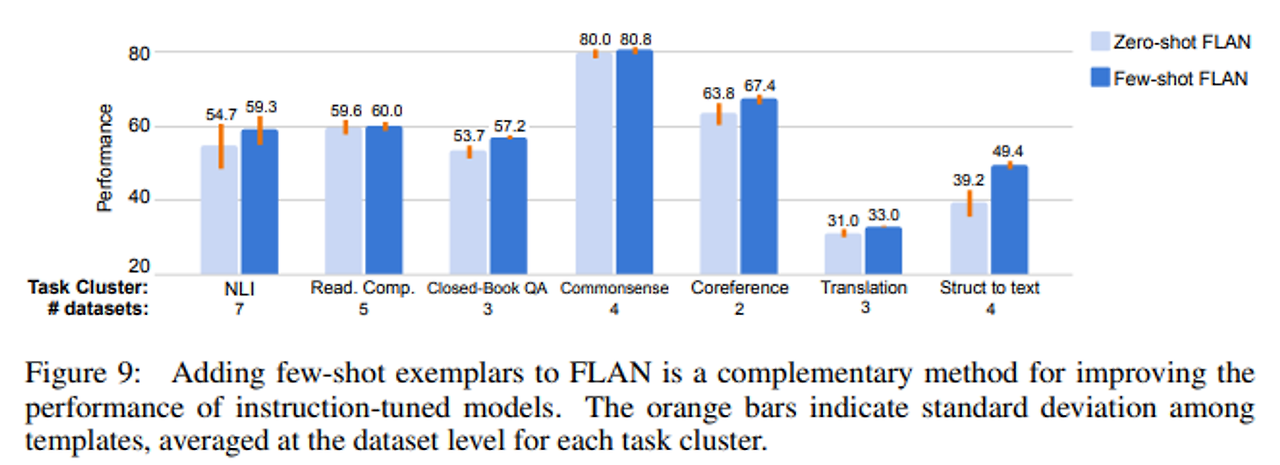
- few-shot 예제는 zero-shot FLAN보다 모든 작업 클러스터에서 성능을 향상시켰으며, 특히 출력 공간이 크거나 복잡한 작업에서 효과적
- few-shot FLAN은 템플릿 간 표준 편차가 낮아져 prompt engineering에 대한 민감도가 줄어드는 것을 확인
[Soft Prompts]
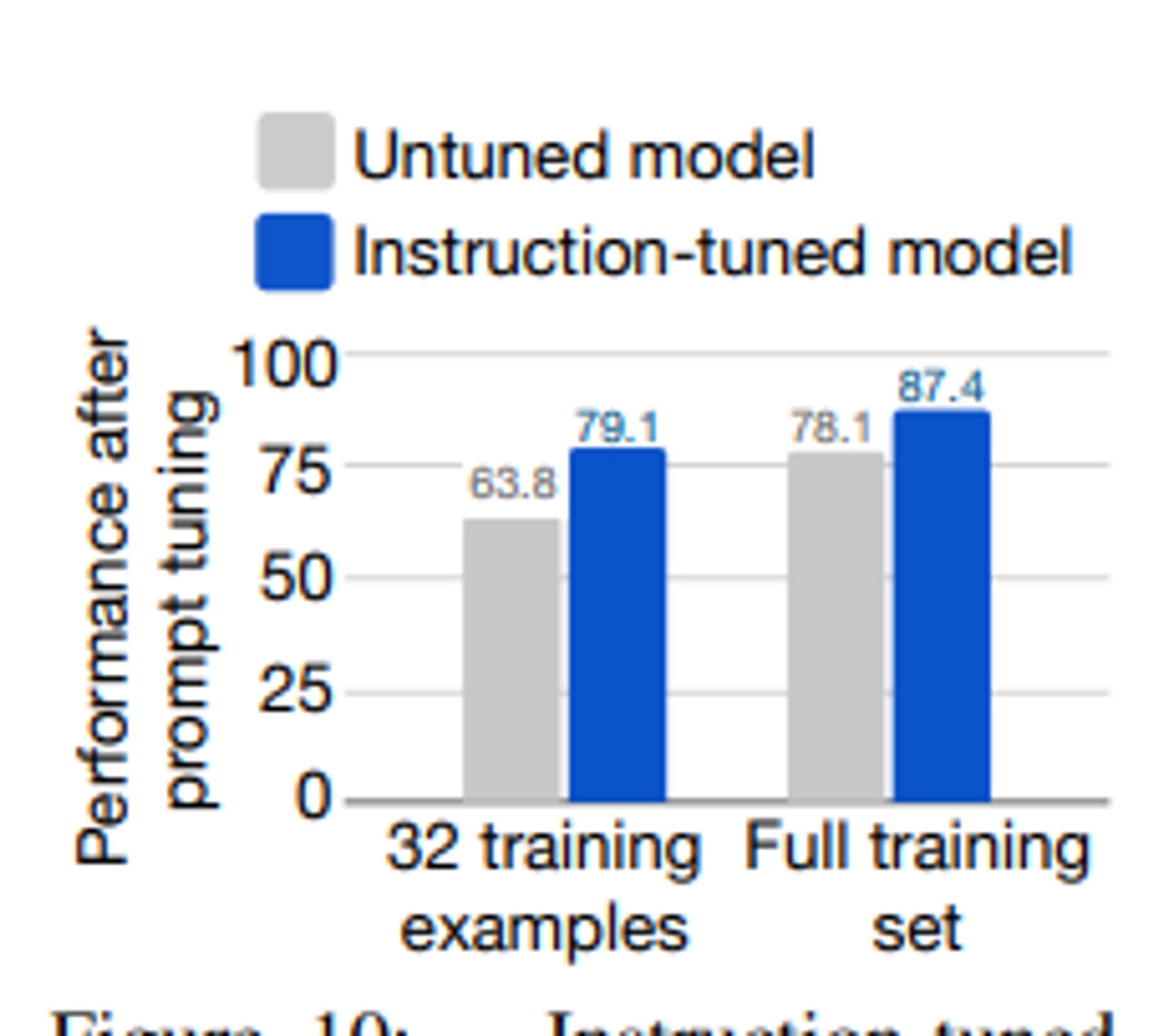
- FLAN은 instruction tuning을 통해 지시에 잘 응답하도록 개선된 모델로, soft prompts를 사용한 추론에서도 더 나은 성능을 보임
- SuperGLUE 작업에 대해 프롬프트 튜닝을 실시한 결과, FLAN은 LaMDA-PT보다 전반적으로 더 우수한 성능을 보임
- 특히 저자원 환경에서는 FLAN의 프롬프트 튜닝이 LaMDA-PT에 비해 10% 이상의 성능 향상을 보였습니다. ⇒ instruction tuning이 NLP 작업에서 유용한 모델을 만드는 데 도움이 됨을 보여줌
[4. 논문의 기여점 및 한계점]
1) 기여점
- Instruction Tuning의 효과: instruction tuning이라는 방법을 통해 언어 모델의 제로샷 성능을 개선하는 간단한 접근법을 제시. FLAN이라는 instruction-tuned 모델이 성능이 개선되었고, 대부분의 평가 작업에서 제로샷 GPT-3를 초과하는 결과를 보임.
- 프롬프트 방법과의 조합: instruction tuning은 few-shot prompting 및 prompt tuning과 같은 다른 프롬프트 방법과 결합하여 사용 가능 → 다양한 프롬프트 방법이 모델 성능에 긍정적인 영향을 미칠 수 있음을 보여줌
- 전반적인 모델 학습 전략: 연구는 전문 모델(각 작업별 모델)과 일반 모델(여러 작업을 수행하는 하나의 모델) 간의 트레이드오프를 논의하며, labeled data를 사용하여 일반 모델이 다양한 새로운 작업을 수행할 수 있도록 돕는 방법을 제시
- 미래 연구 방향: 향후 연구는 더 많은 작업 클러스터 수집 및 생성, 교차 언어 실험, FLAN을 통한 데이터 생성 및 모델의 편향과 공정성 개선을 위한 파인튜닝을 포함할 수 있다.
2) 한계점
- Task 클러스터링의 주관성: 작업을 클러스터에 할당하는 과정에 주관성이 있을 수 있으며, 이는 문헌에서 채택된 분류법을 사용하더라도 정확성을 보장하기 어려울 수 있음
- 짧은 Instruction의 사용: 연구에서는 상대적으로 짧은 지침(일반적으로 한 문장)만 사용했으며, 자세한 지침을 제공하는 것과 비교해 보지는 않음.
- 사전학습 데이터의 중복: 개별 예제가 모델의 사접학습 데이터에 포함되었을 가능성이 있으며, 이는 결과에 영향을 미칠 수 있다. 그러나 후속 분석에서는 데이터 중복이 성과에 큰 영향을 미치지 않는 것으로 보임.
- 비용 문제: FLAN의 137B 규모로 인해 모델을 운영하는 데 높은 비용이 들며, 이는 실용적인 측면에서 제약이 될 수 있음.