 컴퓨터 비전에는 어떤 Task가 있을까?
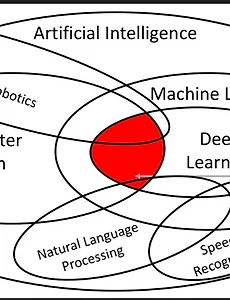
인공지능 분야인공지능 분야 안에도 머신러닝, 딥러닝뿐만 아니라자연어처리, 음성인식, 로보틱스, 컴퓨터 비전 등 다양한 분야가 있습니다. 머신러닝과 딥러닝은 이미 아실 것이라는 가정 하에 다른 분야들을 매우 간결하게 이해하자면,자연어처리는 말 그대로 자연어(텍스트)를 처리하는 Task들을 수행하는 기법이고,컴퓨터 비전은 Vision이라는 말대로, 시각적으로 보이는 것을 다루는 영역입니다.요즘은 멀티모달이라고, 다양한 데이터셋을 합쳐서 Task를 수행하기도 합니다.예를 들면, 이미지를 주고 텍스트로 이미지에 대해 요약해달라고도 하고, 텍스트로 이미지를 생성해달라고도 하면 해줍니다. 저희에게 밀접하게 느껴지는 ChatGPT가 그런 역할을 요즘 해주고 있죠. 멀티모달은 현재 핫한 연구 분야입니다.하지만, 본 포..
2025. 3. 21.
컴퓨터 비전에는 어떤 Task가 있을까?
인공지능 분야인공지능 분야 안에도 머신러닝, 딥러닝뿐만 아니라자연어처리, 음성인식, 로보틱스, 컴퓨터 비전 등 다양한 분야가 있습니다. 머신러닝과 딥러닝은 이미 아실 것이라는 가정 하에 다른 분야들을 매우 간결하게 이해하자면,자연어처리는 말 그대로 자연어(텍스트)를 처리하는 Task들을 수행하는 기법이고,컴퓨터 비전은 Vision이라는 말대로, 시각적으로 보이는 것을 다루는 영역입니다.요즘은 멀티모달이라고, 다양한 데이터셋을 합쳐서 Task를 수행하기도 합니다.예를 들면, 이미지를 주고 텍스트로 이미지에 대해 요약해달라고도 하고, 텍스트로 이미지를 생성해달라고도 하면 해줍니다. 저희에게 밀접하게 느껴지는 ChatGPT가 그런 역할을 요즘 해주고 있죠. 멀티모달은 현재 핫한 연구 분야입니다.하지만, 본 포..
2025. 3. 21.





