<논문> Attention Is All You Need
Attention Is All You Need
The dominant sequence transduction models are based on complex recurrent or convolutional neural networks in an encoder-decoder configuration. The best performing models also connect the encoder and decoder through an attention mechanism. We propose a new
arxiv.org
<제안 모델> Transformer
<논문 리뷰 목차>
- 배경
- 기존 모델 한계 소개
- 한계점을 극복한 제안 모델 소개
- 제안모델
- Transformer 모델 아키텍처
- Multi-Head self-attention
- 활용되는 주요 개념
- Attention
- *Scaled Dot-Product Attention
- Multi-Head Attention 개념
- 활용되는 주요 개념
- Feed-Forward Network
- Positioning Encoding
- 평가 결과 분석
- 논문의 기여점 및 한계점
- 느낀점
[1. 배경]
1) 기존 모델들의 한계
- 기존 모델 - Extended Neural GPU, ByteNet, ConvS2S 등:
- 특징
- Convolutional Neural Networks (CNNs) 사용: CNN을 기본 구성 요소로 사용, 입력 및 출력 위치에 대해 병렬적으로 숨겨진 표현을 계산
- 단점
- 관계 연산의 복잡성: 입력 또는 출력 위치의 두 신호 간의 관계를 계산하는 데 필요한 연산 수가 위치 간 거리와 함께 증가
- ConvS2S: 선형적으로 증가
- ByteNet: 로그적으로 증가
- 먼 위치 간의 의존성 학습 어려움: 먼 위치 간의 의존성을 학습하는 것이 어려움
- 관계 연산의 복잡성: 입력 또는 출력 위치의 두 신호 간의 관계를 계산하는 데 필요한 연산 수가 위치 간 거리와 함께 증가
- 특징
2) 제안 모델, Transformer
- 기존 모델 단점을 극복함
- Multi-Head Attention을 사용하여, 거리가 먼 state 반영 가능해짐
- Side Effects
- 상수 연산 복잡도 감소: 두 위치 간의 신호 관계를 계산하는 데 필요한 연산 수가 상수로 줄어든다
- 유효 해상도 감소: Attention-weighted 위치의 평균화로 인해 유효 해상도 감소
[2. 제안 모델]
- Key Points: Multi-Head Attention, Feed-Forward Networks, Positional Encoding
1) Transformer 모델 아키텍처

- Auto-regressive sequence: 지금까지 생성한 것을 다시 input으로 넣어 다음 생성
- encoder-decoder structure
- Encoder: 2 sub-layers
- “Multi-Head self-attention” mechanism
- Fully connected “Feed-Forward Network”
- Decoder: 3 sub-layers
- “Multi-Head self-attention” mechanism
- Fully connected “Feed-Forward Network”
- Encoder 출력결과에 대한 “Multi-Head self-attention” - Encoder와 차이점
- Encoder: 2 sub-layers
2) Multi-Head self-attention
1. 활용되는 주요 개념
- Attention
- Attention: 어떻게 가중치를 부여하여 활용한 것인지 결정하는 매커니즘
- output과 query, key, value를 mapping
- query, key, value는 다 vector
- output는 value에 대한 가중치의 합
- Attention: 어떻게 가중치를 부여하여 활용한 것인지 결정하는 매커니즘
- *Scaled Dot-Product Attention
- Attention 계산 방법
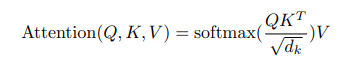
- 각 토큰 임베딩을 query, key, value 벡터로 projection
- Attention 점수 계산 → 가중치 계산
- query와 key 백터 내적를 통해 유사도 계산 → Q· K^T / sqrt(dim_k)
- (참고) key dimension을 임의로 dim_k로 표현함
- sqrt(dim_k) 는 scaling factor이다
- scaling factor는 훈련과정에서 그래디언트를 안정적이게 함
- 이를 통해 (dim_k * dim_k) Attention 점수 행렬이 산출됨
- 토큰이 n개 인 경우, 모양이 n*n인 어텐션 점수 행렬이 산출됨
- Softmax 함수를 적용 → query,key 유사도 점수가 확률값으로 바뀜(열의 합이 1)
- softmax( Q· K^T / sqrt(dim_k)) ⇒ 각 가중치가 된다
- Output 계산: 구한 가중치를 value에 적용 → 가중 평균을 계산
- softmax( Q· K^T / sqrt(dim_k)) V
- Attention 계산 방법
2. Multi-Head Attention 개념
- Multi-Head Attention는 *Scaled Dot-Product AttentionScaled Dot-Product Attention를 여러개(head)를 둔 것
- 하나의 attention function보다 더 유용함
- query, key, value에 대해 각 각에 대해 병렬적으로 attention function 수행
- 독립적으로 수행후 concat

- 논문에서는 8개 head 사용 ⇒ 512 dim / head의 개수 = 512/8= 64
- dim_k = dim_v ⇒ 64 차원
- head의 차원수가 줄어들어서 computational cost는 single-head attention와 비슷
3) Feed- Forward Network
- 독립적으로 수행됨
- 역할: 유사성 검사 후, 추출된 정보를 모델링해서 정보들간의 interaction 확인하는 것
- 토큰의 위치와 상관없이 모든 토큰 임베딩에 병렬적으로 적용됨

4) Positioning Encoding
- Seqeunce의 순서(위치)에 대한 정보 활용 ⇒ 토큰 사전에 위치 정보를 추가해줌
- embedding의 모델 차원과 동일하게 하여, Token embeds에 더할 수 있게 해줌
- Positioning Encoding 방법들
- sine, consine 함수 사용

- 학습된 Positioning Embedding 사용하는 방법
- sine, consine 함수 사용
[3. 평가결과 및 분석]
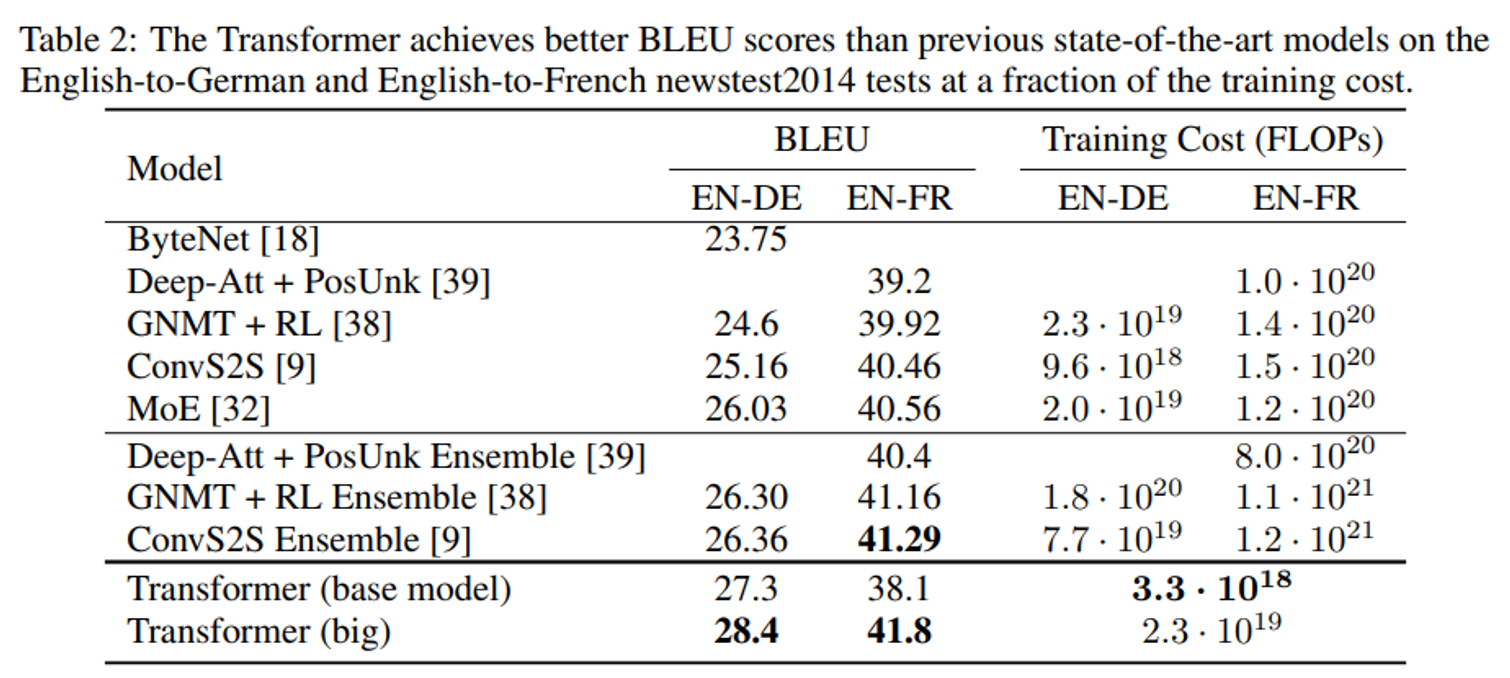
1. Transformer 사용시, 최근 가장 높은 결과를 보인 기존 모델보다 더 좋은 결과가 도출됨
2. 세부 테스트 결과
- (A) head 너무 적거나 많을 경우 성능 떨어짐
- (B) Attention key 사이즈를 줄이면 모델 성능 떨어짐
- (C) 모델이 클수록 결과가 좋다
- (D) dropout하는 것이 좋다
- (E) 학습된 위치 임베딩을 사용하는 것과 결과 비슷 → So, sinusoid를 활용하는 것이 더 좋다. (위에서 이미 설명함)

[4. 논문의 기여점 및 한계점]
1) 기여점
- 순환(recurrence)과 합성곱(convolution)의 제거:
- Transformer 모델은 기존의 RNN(Recurrent Neural Networks)이나 CNN(Convolutional Neural Networks)과 달리, 순환과 합성곱을 사용 x
- 순환 구조를 제거하고 완전한 어텐션 메커니즘을 사용함으로써, Transformer 모델은 GPU를 활용한 병렬 처리가 가능해짐 → 훈련 시간을 크게 단축
- Self-Attention 메커니즘:
- Self-Attention 메커니즘을 사용하여 시퀀스 내의 모든 위치 간의 의존성을 한 번에 계산→ 멀리 떨어진 위치 간의 관계를 더 효율적으로 학습
- Multi-Head Attention:
- 다중 헤드 어텐션을 사용하여 다양한 표현 공간에서 어텐션을 계산하고, 이를 통합하여 더 풍부한 표현을 얻음 → 모델의 성능을 크게 향상시키는 중요한 요소
- Positional Encoding:
- 시퀀스의 각 위치에 대한 정보를 추가로 제공하여, 모델이 시퀀스의 순서 정보를 효과적으로 학습
- NLP 분야에 다양한 발전을 이끌어낼 수 있는 새로운 방향성을 제시함
2) 한계점
- 이미지, 영상과 같은 큰 input, output을 다루지 못함
[5. 느낀점]
지난번에 Transformer을 공부할 때는 논문의 전반적인 흐름을 이해했다면, 이번에는 조금 더 세세하게 수식과 평가결과들을 이해할 수 있어서 좋았다.
또한 이번에는 Attention 자체에 좀 더 포커스하여 분석하였는데,
RNN의 한계점인 1. 거리가 먼 부분은 마지막 state에 반영이 거의 되지 않는 문제와 2. 순차적으로 처리할 수 밖에 없었던 부분들을 Attention이 해결해준다는 포인트에서 Attention이 더욱 매력적이게 느껴졌다.