논문 제목: BERT4Rec: Sequential Recommendation with Bidirectional Encoder Representations from Transformer
BERT4Rec: Sequential Recommendation with Bidirectional Encoder...
BERT4Rec: Sequential Recommendation with Bidirectional Encoder Representations from Transformer
Modeling users' dynamic and evolving preferences from their historical behaviors is challenging and crucial for recommendation systems. Previous methods employ sequential neural networks (e.g., Recurrent Neural Network) to encode users' historical interact
arxiv.org
BERT4Rec: Sequential Recommendation with Bidirectional Encoder Representations from Transformer | Notion
논문 제목: BERT4Rec: Sequential Recommendation with Bidirectional Encoder Representations from Transformer
button-breeze-d77.notion.site
<논문 리뷰 목차>
- 배경
- 선행 모델의 문제점
- 제안 모델의 차별점
- 제안모델
- 문제 정의
- 모델 아키텍처
- 모델 학습 방식
- 모델 평가
- 사용한 데이터셋
- 사용한 평가방법 및 평가지표
- 비교 모델
- 평가 결과 분석
- 논문의 기여점 및 한계점
- 기여점
- 한계점
- 느낀점
[1. 배경]
1) 선행 모델의 문제점
-
-
- 추천시스템에서 Sequential Dynamics의 중요성
- 사용자의 관심은 동적이고 진화한다
- 이러한 사용자의 Sequential Dynamic한 태도를 반영하고자 많은 선행 모델이 제안되었다
- 사용자의 과거 행동을 반영하고자 함
- 선행 모델 특징
- left-to-right unidirectional model 사용 (ex. RNN)
- 선행 모델: Basic paradigm
- 사용자의 과거 interactions를 벡터로 encode
- left-to-right unidirectional model 사용하는 추천시스템
- left-to-right unidirectional model 단점
- 사용자의 행동 시퀀스에서 숨겨진 표현의 능력을 제한
- 종종 엄격하게 순서가 정해진 시퀀스를 가정하는데, 이는 항상 실용적이지는 않다
- 선행 모델
- [1. General Recommendation 2. Sequential Recommendation 3. Attention Recommendation]
- General Recommendation
- 과거: Collaboratrive Filtering(CF) 주로 사용
- ex. Matrix Factorization, item-based neighborhood methods
- 최근: Deep-Learning 활용
- 한계점: Sequential Recommendation을 위한 것이 아니다
- Sequential Recommendation
- 과거: Markovchains(MCs) 사용
- 최근: RNN, Gated Reccurent Unit(GRU), Long Short-Term Memory(LSTM)
- 한계점: unidirectional model
- Attention → Sequential 데이터에 잠재력 보임
- 과거: attention mechanism을 기존 모델의 추가적인 요소로 사용
- 최근: 순수하게 attention-based NN을 활용
- SASRec → 제안모델과 유사, 한계점: unidirectional model
- 추천시스템에서 Sequential Dynamics의 중요성
-
2) 제안 모델의 차별점
-
-
- Cloze를 활용하여 추천시스템에 Bidirectional Model 사용
- 장점
- Global receptive field: 입력 시퀀스의 모든 위치 간의 관계를 한 번에 고려 가능
- 병렬적 수행

- 장점
- 유사 모델과의 차별점
- SASRec:
- SASRec는 unidirectional ↔ BERT4Rec는 bidirectional
- 다른 훈련 방법: SASRec는 시퀀스 내 각 위치에서 다음 항목을 예측 ↔ BERT4Rec은 Cloze Objection 사용하여 시퀀스 내 마스킹된 항목을 예측
- Continous Bag-of-Words(CBOW) & Skip-Gram(SG)
- Cloze는 CBOW와 SG의 목적을 위한 일반화된 형태
- CBOW
- CBOW는 맥락(좌우 모두)의 모든 단어 벡터의 평균을 사용하여 목표 단어를 예측
- CBERT4Rec의 단순화된 사례 → BERT4Rec에서 하나의 self-attention 레이어를 사용, 항목에 대해 균일한 어텐션 가중치를 적용, item 임베딩을 공유 x, 위치 임베딩 제거, 중앙 항목만 마스킹하는 경우
- SG(Skip-Gram)
- BERT4Rec의 단순화된 사례 → BERT4Rec에서 하나의 item만 제외하고 모든 항목을 마스킹한 경우
- 다른 학습 목표(목적)
- CBOW는 좋은 단어 표현을 학습하는 것이 목표이기 때문에 단어 시퀀스를 모델링하는 간단한 집합 연산기를 사용 ↔ BERT4Rec는 추천을 위해 강력한 행동 시퀀스 표현 모델(본 연구에서는 심층 self-attention 네트워크)을 학습하고자 함.
- SASRec:
- Cloze를 활용하여 추천시스템에 Bidirectional Model 사용
-
[2. 제안모델]
1) 문제 정의
- 목표: S_u라는 history가 주어졌을때, n_u +1 시간에 user u가 상호작용할 item을 예측하는 것

- 가능한 모든 items에 대해 확률을 구함
2) 모델 아키텍처
- 구성: Embedding Layer → Transformer Layer → Output Layer
- [Transformer Layer]hidden representations of each layer
- [Embedding Layer &Transformer Layer] 모든 위치 간의 정보를 계층적으로 교환
- [Output Layer] 예측
[Transformer Layer 설명]
- TRM: 2 Sublayers( 1. Multi-Head Self-Attention 2. Position-wise Feed-Forward Network 사용)
- Multi-Head Self-Attention 사용

- 사용 이유: 다른 position과 representation subspace에 있는 정보를 공동으로 참조하는 것이 유익하다 → single Attention이 아닌, Multi-Head Self-Attention 사용
- 사용 이유: 다른 position과 representation subspace에 있는 정보를 공동으로 참조하는 것이 유익하다 → single Attention이 아닌, Multi-Head Self-Attention 사용
- Attention Function: Scaled Dot-Product Attention

- sqrt(d/h) 는 scaling factor이다 → 훈련과정에서 소멸 그레디언트를 피할 수 o (안정적)

- sqrt(d/h) 는 scaling factor이다 → 훈련과정에서 소멸 그레디언트를 피할 수 o (안정적)
- Position-wise Feed-Forward Network 사용
- 각 위치별로 동일하게 Position-wise Feed-Forward Network 적용
- 사용 이유: 모델에 비선형성과 서로 다른 차원 간의 상호작용을 부여하기 위함
- 활성화 함수 : Gaussian Error Linear Unit(GELU) 사용

- Stacking Transformer Layer
- 사용 이유: Self-Attention 매커니즘은 item끼리의 상호작용을 잘 파악하지만, 복잡한 패턴을 분석하는데 더 유리하다.
- 단점: layer가 많이 쌓일 수록 학습하기 어려워짐
- 보완: Layer Normalization & Dropout 실행
- sublayer의 output:

- sublayer의 output:
- Summary : hidden representations of each layer

- 추천시스템에서의 Transformer Layer의 한계 : Transformer layer Trm은 입력의 순서를 고려하지 x
- 해당 문제점 보완 → 입력에 Positional Embedding 추가
- Positional Embedding 장점: input의 어떠한 부분을 처리하고 있는지 식별 가능하게 함
[Embedding Layer 설명]
- Positional Embedding 사용→ input item (v) embedding에 position embedding(p) 추가
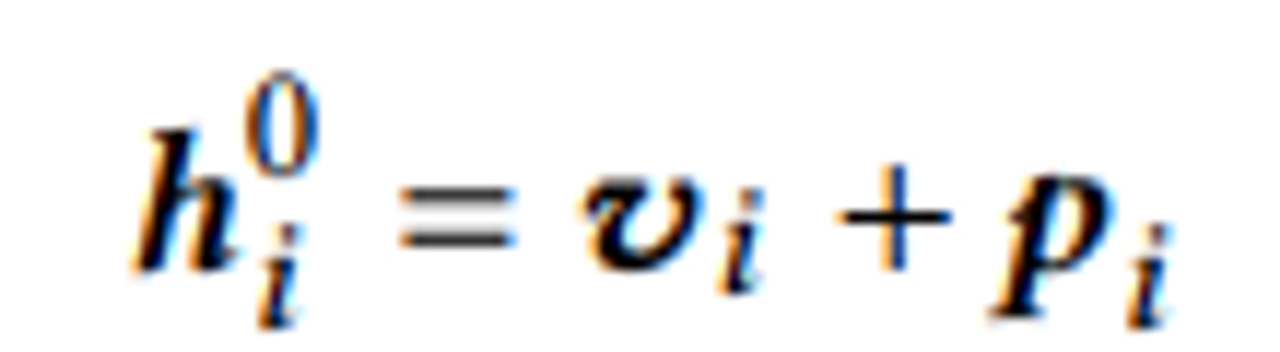
input item (v) embedding에 position embedding(p) 추가 - 사용 이유: 입력의 순서를 고려한 Sequential information를 이용하기 위함
- 한계점: 모델이 다룰 수 있는 문장의 최대 길이(N)에 제한 존재
- 해결 방안: item t 길이가 N보다 크면, truncate 진행
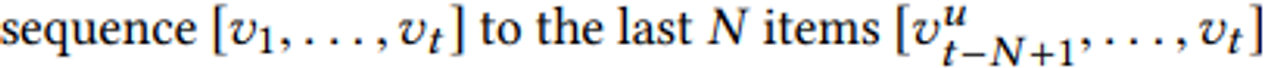
[Output Layer 설명]

- 변수 설명


- 공유된 item embedding matrix 사용 이유: 과적합을 완화하고 모델 크기를 줄이기 위해
- 각 item v에 대한 예측 진행
- 시간 단계 t에서 item v_t를 마스크한다고 가정하면, h^L_t를 기반으로 마스크된 항목 v_t를 예측
- 두 개의 피드포워드 네트워크를 GELU 활성화를 통해 적용하여 목표 항목에 대한 출력 분포를 생성
3) 모델 학습 방식
KeyPoint: Cloze Task
[학습 방식]
- 선행연구(unidirectional model) 학습 방식
- 다음 item을 예측하는 방식으로 학습시킨다
- 제안모델(bidirectional model)의 문제점
- item의 output representaion에 목표하는(예측해야하는) item의 정보를 포함하게 된다 → 즉, 미래를 예측을 위해 학습하는 것이 의미 x
- 해결방안 1 & 문제점
- 해결방안1: 기존 t 길이의 시퀀스에서 t-1 샘플만을 생성하기
- 문제점 : 각 위치에 따른 샘플을 많들고 예측하는 것이 많은 시간과 자원이 소모된다
- 해당 논문이 제안하는 해결방안 : “Cloze Task = Masked Language Model”
- “Cloze Task = Masked Language Model” 설명
- 일부 단어가 제거된 시퀀스으로 test하는 방식으로, 참가자가 제거된 단어들을 채워야하는(예측하는) 방식이다

- 일부 단어가 제거된 시퀀스으로 test하는 방식으로, 참가자가 제거된 단어들을 채워야하는(예측하는) 방식이다
- 장점
- 모델을 학습시키기 위한 샘플들을 더 생성할 수 있다
- 선행 모델의 경우 n개의 샘플
- Masked 사용시 nCk의 샘플 생성 (k: 랜덤하게 mask된 item 개수)
- 모델을 학습시키기 위한 샘플들을 더 생성할 수 있다
- 활용 방식
- masked된 입력 S_u’에 대한 loss를 negative log-likelihood로 정의

- ( S'_u )는 사용자 행동 이력인 (S_u)의 마스크된 버전
- ( S^m_u )는 그 안에서 랜덤하게 마스크된 항목들
- ( v^*_m )은 마스크된 항목인 ( v_m )의 실제 항목
- 확률 P는 모델의 output layer에서 softmax를 거쳐서 나온 최종 결과
- masked된 입력 S_u’에 대한 loss를 negative log-likelihood로 정의
- “Cloze Task = Masked Language Model” 설명
[테스트 방식]
- 문제 사항: Cloze objective는 현재 masked된 item을 예측하는 방식이고, Sequential 추천 시스템의 방식을 미래를 예측하는 것에서 차이점 발생
- 해결방안:
- 사용자의 행동 시퀀스 뒤에 [mask]라는 special token 추가
- 마지막 item을 더 잘 예측하기 위해, 마지막 item만을 mask한 시퀀스를 학습과정 중에 생성
[3. 모델 평가]
1) 사용한 데이터셋
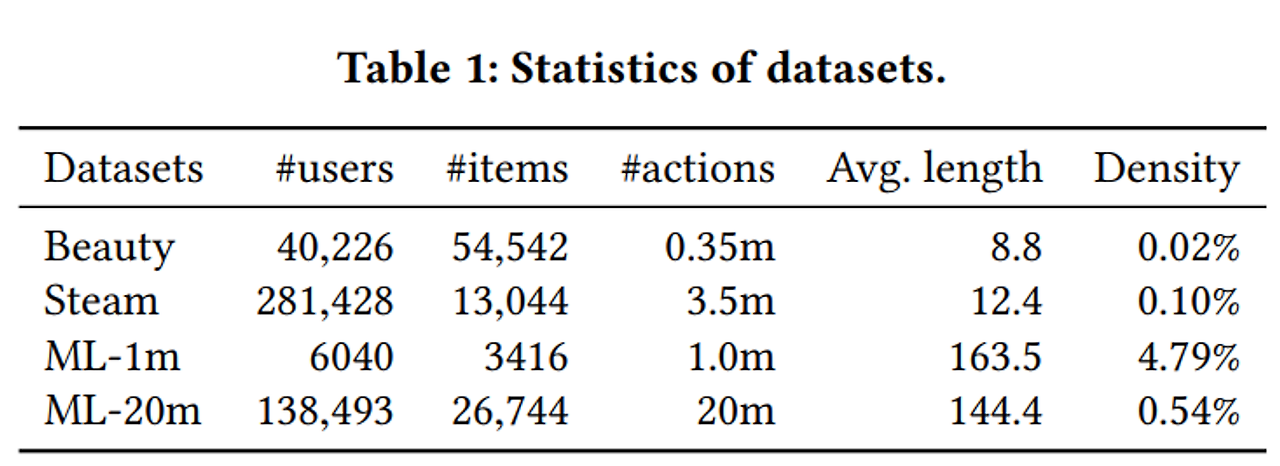
- Beauty: Amazon 제품 리뷰 데이터셋
- Steam: 대형 온라인 비디오 게임 플랫폼 데이터셋
- MovieLens: 추천 알고리즘을 평가를 benchmarking한 유명한 데이터셋
2) 사용한 평가방법 및 평가지표
- 평가 방법
- leave-one-out evaluation (i.e., next item recommendation) task 채택
- 각 사용자에 대한 행동 시퀀스의 마지막 item을 테스트 데이터로 보류하고, 마지막 바로 전 item을 검증 세트로 간주하며, 나머지 item을 학습에 활용
- 테스트 세트의 각 실제 항목을 사용자가 상호작용하지 않은 100개의 무작위로 샘플링된 negative item과 짝지어 평가
- negative item이란? : 사용자가 상호작용하지 않았거나 관심이 없다고 간주되는 item
- 100개의 부정 항목은 그들의 인기도에 따라 샘플링 = 각 사용자의 실제 항목과 부정 항목들을 순위 매김 → 샘플링의 신뢰성과 대표성을 높이기 위함
- leave-one-out evaluation (i.e., next item recommendation) task 채택
- 평가 지표
- Hit Ratio (HR) - Recall@k와 동일, Precision@k에 비례
- Normalized Discounted Cumulative Gain (NDCG)
- Mean Reciprocal Rank (MRR) - Mean Average Precision (MAP)과 동일
- HR과 NDCG를 k = 1, 5, 10으로 평가
- 모든 지표에 대해 value가 높을수록 성능이 더 좋다.
3) 비교 모델
| 비교모델 | 설명 |
| POP | 가장 간단한 기준선 모델로, 항목의 인기도를 상호작용 횟수로 판단하여 순위를 매김 |
| BPR-MF [39] | 암시적 피드백을 사용하여 행렬 분해를 최적화하며, pairwise ranking loss 사용 |
| NCF [12] | 행렬 분해에서 내적 대신 다층 퍼셉트론(MLP)을 사용하여 사용자-항목 상호작용을 모델링합니다. |
| FPMC [40] | 행렬 분해와 1차 마코프 체인(MCs)을 결합하여 사용자의 일반적인 취향과 순차적 행동을 포착 |
| GRU4Rec [15] | 순차적 추천을 위해 랭킹 기반 손실을 사용하는 GRU(게이트 순환 유닛) 모델을 사용 |
| GRU4Rec+ [14] | GRU4Rec의 개선된 버전으로, 새로운 종류의 손실 함수와 샘플링 전략을 포함 |
| Caser [49] | 순차적 추천을 위해 수평적 및 수직적 방식으로 CNN(합성곱 신경망)을 사용하여 고차 마코프 체인을 모델링 |
| SASRec [22] | 사용자의 순차적 행동을 포착하기 위해 왼쪽에서 오른쪽으로 Transformer 언어 모델을 사용, 순차적 추천에서 최신 성능을 달성함 |
4) 평가 결과 분석
- 모든 데이터셋에서 제안모델이 가장 좋은 성능을 보임

- bidirectional과 Cloze 중 어느 것이 성능 개선을 불러오는 걸까? - unidirectional 모델(SASRec)보다 Bert4Rec(1mask)가 좋은 성능 보임 → bidirectional이 성능 개선을 불러옴
- Cloze Objection도 성능을 개선시킴
- Bidirectional Model이 왜 unidirectional 모델보다 더 좋은 성능을 보일까? unidirectional 모델은 왼쪽 항목에만 주의를 기울일 수 있는 반면, Bidirectional Model은 양쪽 item에 주의를 기울이기 때문에 더 성능을 보인다.

분석 결과 (근거)
- attention은 서로 다른 헤드들 간에 다르게 나타남
- ex) (a) Layer 1, head 1은 왼쪽 항목에 주로 주의를 기울이는 반면, (b) Layer 1, head 2는 오른쪽 항목에 주의를 기울이는 경향 보임
- attention은 서로 다른 레이어들 간에도 다르게 나타남
- Layer 2에서는 더 최근의 항목에 주의를 집중하는 경향 존재
- 이유 분석: Layer 2가 출력 레이어와 직접 연결되어 있고, 최근 항목이 미래를 예측하는 데 더 중요한 역할을 하기 때문
- Layer 2에서는 더 최근의 항목에 주의를 집중하는 경향 존재
- (a) , (b) 에서 Head가 [mask]에 주의를 기울이는 경향 존재
- 이유 추정: Self-Attention가 시퀀스 수준의 상태를 item level로 전파하는 방법일 수 있다.
- 단방향 모델이 왼쪽 항목에만 주의를 기울일 수 있는 반면, BERT4Rec의 항목들은 양쪽 항목에 주의를 기울이는 경향 존재 → Bidirectional Model은 사용자 행동 시퀀스 모델링에 필수적이고 유익하다는 것을 보여준다
[4. 논문의 기여점 및 한계점]
1) 기여점
- Bidirectional self-attention Architecture:
- 양쪽 문맥을 모두 활용해 Sequential Recommendation 성능을 향상시켰다.
- Cloze 과제 도입:
- 좌우 문맥을 사용하여 마스킹된 아이템을 예측하는 Cloze Task를 통해 모델 훈련의 효과를 높였다.
- 우수한 성능:
- 네 가지 실제 데이터셋에서의 실험 결과, BERT4Rec이 기존 최신 기법들의 성능을 능가
2) 한계점
- 아이템 특성 미활용:
- 현재는 아이템 ID만을 모델링하고 있어, 카테고리, 가격, 출연진 등 풍부한 아이템 특성을 통합하지 못하고 있다.
- 사용자 구성 요소 부재:
- 사용자가 여러 세션을 가질 때, 명시적인 사용자 모델링을 위한 사용자 구성 요소가 모델에 포함되어 있지 않다.
- 복잡한 모델:
- 깊은 양방향 자기 주의 아키텍처와 Cloze 과제를 사용함에 따라, 모델의 복잡성과 계산 비용이 증가할 수 있다.
- 데이터 의존성:
- 실험 결과는 네 가지 데이터셋에 기반하고 있어, 다른 종류의 데이터셋에 대한 일반화 성능이 보장되지 않을 수 있다.
[5. 느낀점]
추천시스템에도 Attention 기법을 적용하는 접근방식이 새로웠다.
다양한 text task과 비전에서 Attention을 적용하는 방향을 주로 접했는데, Transformer의 장점이 다른 AI 분야에서도 다양하게 쓰일 수 있는 것을 인지하게 되서 의미 있었다고 생각한다.
앞으로 접목될 수 있는 분야와 발전 가능성이 매우 기대된다🙂