Jiang, Xi, et al. "Softpatch: Unsupervised anomaly detection with noisy data." Advances in Neural Information Processing Systems 35 (2022): 15433-15445.
SoftPatch: Unsupervised Anomaly Detection with Noisy Data (neurips.cc)
SoftPatch: Unsupervised Anomaly Detection with Noisy Data
Requests for name changes in the electronic proceedings will be accepted with no questions asked. However name changes may cause bibliographic tracking issues. Authors are asked to consider this carefully and discuss it with their co-authors prior to reque
proceedings.neurips.cc
Abstract:
Although mainstream unsupervised anomaly detection (AD) algorithms perform well in academic datasets, their performance is limited in practical application due to the ideal experimental setting of clean training data. Training with noisy data is an inevitable problem in real-world anomaly detection but is seldom discussed. This paper considers label-level noise in image sensory anomaly detection for the first time. To solve this problem, we proposed a memory-based unsupervised AD method, SoftPatch, which efficiently denoises the data at the patch level. Noise discriminators are utilized to generate outlier scores for patch-level noise elimination before coreset construction. The scores are then stored in the memory bank to soften the anomaly detection boundary. Compared with existing methods, SoftPatch maintains a strong modeling ability of normal data and alleviates the overconfidence problem in coreset. Comprehensive experiments in various noise scenes demonstrate that SoftPatch outperforms the state-of-the-art AD methods on the MVTecAD and BTAD benchmarks and is comparable to those methods under the setting without noise.
Abstract 번역본(by ChatGPT):
unsupervised anomaly detection (AD) 알고리즘은 학술적 데이터셋에서는 잘 작동하지만, 실제 응용에서는 깨끗한 훈련 데이터의 이상적인 실험 설정으로 인해 성능이 제한됩니다. 노이즈 데이터로 훈련하는 것은 현실 세계에서의 이상 탐지에서 불가피한 문제지만, 거의 논의되지 않습니다. 본 논문에서는 이미지 센서 이상 탐지에서 라벨 수준의 노이즈를 처음으로 고려합니다. 이 문제를 해결하기 위해, 우리는 메모리 기반 비지도 AD 방법인 SoftPatch를 제안합니다. 이 방법은 효율적으로 패치 수준에서 데이터를 노이즈 제거합니다. 노이즈 디스크리미네이터를 사용하여 패치 수준의 노이즈 제거를 위한 이상 탐지 점수를 생성한 다음, 이 점수는 코어셋 구성 전에 메모리 은행에 저장되어 이상 탐지 경계를 부드럽게 만듭니다. 기존 방법과 비교하여, SoftPatch는 정상 데이터의 강력한 모델링 능력을 유지하고 코어셋의 과신 문제를 완화합니다. 다양한 노이즈 환경에서의 포괄적인 실험 결과는 SoftPatch가 MVTecAD 및 BTAD 벤치마크에서 최신 AD 방법을 능가하고, 노이즈 없는 설정에서는 해당 방법과 유사한 성능을 보여준다는 것을 입증합니다.
본 페이지에서는 해당 연구를 이해의 편의를 위해서 배경 & 기존 모델의 문제점, 제안모델 요약, 관련 선행연구, 제안모델과 실험방법, 평가 결과 분석, 논문의 기여점 순으로 정리합니다. 개인적인 분석이므로, 해당 논문에 대한 평가가 아닌 '해당 논문이 어떠한 내용이다'를 정리한 논문 리뷰로서 참고하고 봐주시면 감사하겠습니다. 더욱 자세한 내용을 위해서는 첨부된 논문을 읽어주세요:) 또한, 해당 모델의 코드가 논문에 첨부되어 있으니 참고하실 분은 참고바랍니다.
특히, 해당 모델의 코드가 공개되어 있습니다. 확인하시고 싶으신 분들을 Github 링크 들어가서 확인해주시면 될 것 같습니다. ( TencentYoutuResearch/AnomalyDetection-SoftPatch: Code for NeurIPS 2022 paper "SoftKernel: Unsupervised Anomaly Detection with Noisy Data" (github.com) )
*선행연구의 논문이 보고 싶다면, 본 논문의 references에서 확인 부탁드립니다:)
언제든 피드백은 환영입니다:)
[배경 & 기존 모델의 문제점]
1. 최근 결함이 작고 수집하기 어려운 산업 응용 분야에서는 Unsupervised sensory anomaly detection(= covariate shift detection) 방법이 제안되어 활발한 연구가 이루어지고 있다.
- 기존의 딥러닝 방법은 주로 AD 문제를 one-class 학습으로 모델링하며, 노이즈 데이터에 대한 견고성이 부족하다.
2. 현실 세계에서는 표준 정상 데이터셋에 노이즈가 스며들어 있는 것은 불가피하며, 특히 매일 대량의 제품이 생산되는 산업 • 제조업에서는 이러한 노이즈가 발생한다. 하지만, 기존 방식의 딥러닝 방식은 이러한 노이즈 데이터에 취약하다.
- 대부분의 기존 Unsupervised AD 방법은 테스트 샘플과 표준 데이터셋 분포 사이의 거리를 측정하여 샘플이 표준 데이터셋과 다른지를 결정한다.
- 이러한 방법들은 최근 우수한 성능을 보였지만, 훈련 데이터에 과도한 신뢰를 하면 함정에 빠질 수 있다.
- 표준 정상 데이터셋에 노이즈 데이터가 포함되면, 추정된 경계가 신뢰할 수 없어지고, 비정상 데이터의 분류 정확도가 낮아진다.
- ex) 최근의 최첨단 방법인 PatchCore[8]는 표준 정상 데이터셋의 원래 CNN 특징을 가장 가까운 검색을 사용하여 하위 샘플링하고 작은 메모리 뱅크로 코어셋을 설정한다. BUT 코어셋 선택 및 분류 프로세스는 오염된 데이터에 취약했다.
결론: 기존의 Unsupervised AD 방법은 훈련 세트를 모델링하는 데 전략적으로 접근하여 노이즈 데이터에 취약하다
[제안모델 요약]
최근에 많은 관심을 받고 있는 Unsupervised sensory anomaly detection[1]에 중점을 두고 있으며, 새로운 작업인 이상 위치 지정을 포함한다. 패치 수준의 선택 전략을 제안하여 노이즈 이미지 패치를 제거하며, 이는 기존의 샘플 수준 노이즈 제거와 달리 비정상적인 패치를 분리하고, 노이즈 샘플의 정상 패치를 활용한다. 패치 수준의 노이즈 제거를 기반으로 한 새로운 AD 알고리즘인 SoftPatch를 제안하여 더 나은 노이즈 견고성을 갖춘다. 이상치 요소를 사용하여 코어셋 예제의 가중치를 다시 조정하여 잘못된 지식을 수정하고 추론을 개선하였다.
[관련 선행연구]
해당 부분은 크게 1. 비지도 이상탐지 2. 노이즈 데이터 학습으로 나뉩니다.
*또한, 각 선행연구를 깊게 다루기보다는 어떠한 선행연구 모델들이 있는지와 논문에서 이야기하는 Insight 위주로 정리되었습니다
1. 비지도 이상 탐지
• 에이전트 작업으로 훈련 = self-supervised learning
- 에이전트 작업은 이상의 범주 및 모양 정보가 없을 때 유용한 해결책이다
Sheynin et al. [13]: 다중 스케일 생성 모델 이후 수평 뒤집기, 이동, 회전 및 회색 변화와 같은 변환을 사용하여 표현 학습을 강화함.
Li et al. [14]: 기존의 self-supervised learning을 단순히 적용하는 것이 지역 결함을 감지하는 데 부적합하다고 언급하며, CutPaste라는 새로운 에이전트 작업을 제안 → 표준 이미지의 패치를 자르고 무작위 위치에 붙여 이상적인 샘플을 시뮬레이션함
DRAEM [15]은 Perlin Noise를 통해 이상을 합성한다. → 그러나 합성된 이상과 실제 이상 사이의 불가피한 차이는 모델의 기준을 방해하고 일반화 성능을 제한함
• Agnostic methods (**지식 축소 & 이미지 재구성** 포함)
- 독립적인 방법은 이상 샘플과 정상 샘플을 동시에 입력할 때 추론에서 모델의 행동이 다를 것이라는 이론을 기반으로 함
**지식 축소**
- 지식 축소는 이상 샘플의 표현이 사전 훈련된 교사 모델과 학생 모델 사이에서 다르다고 제안함
이는 학생 모델이 이상이 없는 훈련 세트로 교사 출력을 모방하려고 노력한다.
Salehi et al. [17]: 축소 중에 여러 중간 출력을 고려하고, 더 작은 학생 네트워크를 사용하면 더 나은 결과를 얻을 수 있다고 제안
Reverse distillation [18]: 재구성 네트워크와 유사한 구조를 가진 학생 모델에 이상 변형을 전파하는 것을 방지하는 역흐름 사용
**이미지 재구성**
Image Reconstruction methods [7; 19; 20]:
- 정상 집합에서 훈련된 재구성 네트워크가 이상 부분을 재구성할 수 없다는 가정을 활용.
- 고해상도 결과를 얻기 위해 재구성된 이미지와 원본 이미지 간의 차이를 비교함으로써 얻을 수 있다.
- 그러나 모든 Agnostic method는 장기간의 훈련 단계가 필요하므로 사용이 제한된다.
즉, fully unsupervised learning에서의 신속한 배포 가정에 영향을 준다.
• 특징 모델링 ( 분포 추정, 분포 변환, 사전 훈련된 모델 적응, 메모리 저장 포함)
특징 모델링의 의미: 추출기의 출력 특징을 직접 모델링하는 것
PaDiM [21]: 정상 데이터의 패치 임베딩을 추정하기 위해 다변량 가우시안 분포를 사용
- 추론 단계에서 비정상적인 패치의 임베딩은 분포를 벗어날 것이다.
- 간단하지만 효율적인 방법이지만, 가우시안 분포는 더 복잡한 데이터 케이스에는 부적합합니다.
DifferNet [23] & CFLOW [9]:
- 다중 스케일 표현을 기반으로 한 가역적인 정규화 흐름을 활용하여 밀도 추정을 향상시킴
Houet al. 26:
- 특징 맵의 분할의 세분성이 정상 및 비정상 샘플의 모델 재구성 능력과 밀접하게 관련있다고 제안
- 과거 데이터의 모델로써 자동 인코더 네트워크에 다중 스케일 블록별 메모리 뱅크를 포함시킴
PatchCore [8]:
- 더 명시적이지만 가치 있는 메모리 기반 방법
- 샘플링된 패치 특징을 메모리 뱅크에 저장하고, 테스트 특징과 코어셋 사이의 최근접 거리를 계산하여 이상 점수를 얻음
- 일반적인 설정에서 PatchCore는 우수한 성능을 보임
- 그러나 훈련 세트에서 overconfident하여 노이즈 강인성이 낮아지는 문제가 있습니다.
2. Learning with Noisy Data
- 잡음 라벨 인식은 지도 학습에서 신생 주제로 부상하고 있지만, 명확한 라벨이 없기 때문에 비지도 이상 탐지에서는 거의 탐구되지 않았다.
[27; 28]: 분류를 위해 높은 신뢰 임계값으로 노이즈가 있는 가짜 라벨 데이터를 걸러 내는 것을 제안함
Li et al. [29]: 혼합 모델을 사용하여 노이즈가 있는 라벨 데이터를 선택하고 준지도 학습 방식으로 훈련
Kong et al. [30]:
- 해로운 훈련 샘플을 다시 라벨링한다.
- 객체 감지에서는 전문가 모델의 지식을 활용하여 multi-augmentation [31], teacher-student [32], contrastive learning [33] 이 노이즈를 완화하는 데 채택됨
[34]:
- 30 개의 AD 알고리즘의 모델 강건성을 탐색함
- 그러나 비지도 방법은 주석 오류 설정에서 제외됨
Pang et al. [35]:
- 수동으로 라벨이 지정되지 않은 데이터에서 비디오 이상을 처리하며 연속 프레임의 정보를 활용
제안모델과 실험방법
제안모델과 기존 모델 비교
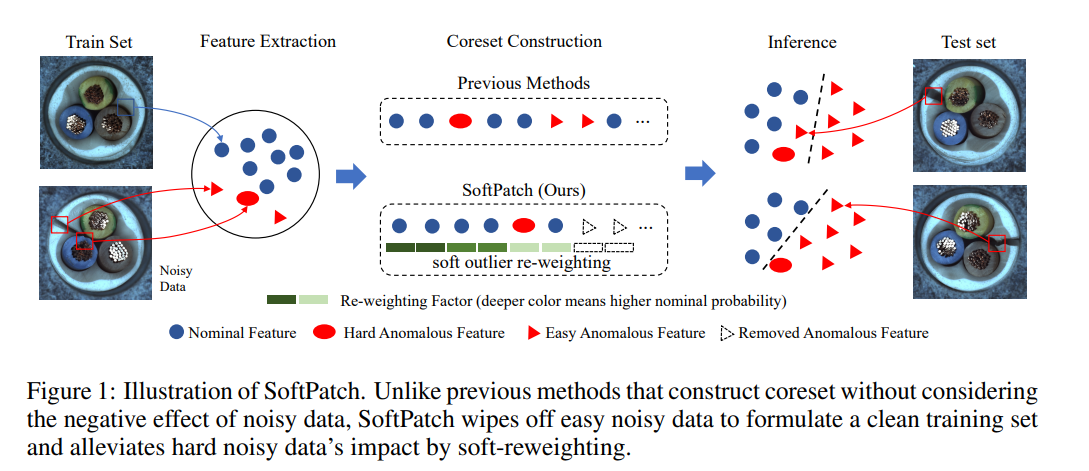
제안 모델 한눈에 보기
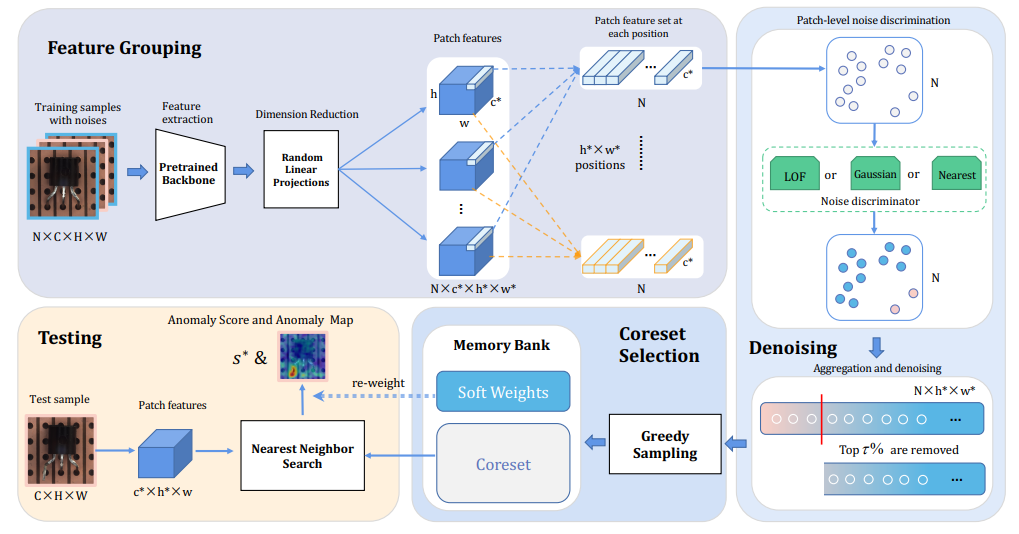
1. 훈련 단계에서는 noise가 특징 맵의 각 위치에서 패치 수준에서 소음 구별자에 의해 구별됨
- 패치 노드가 더 깊은 색상을 가질수록, 그것이 노이즈 패치일 가능성이 높음.
2. 모든 패치에 대한 이상치 점수를 집계하여 노이즈 패치 결정
- 세 가지 노이즈( Nearest Neighbor, Multi-Variate Gaussian, Local Outlier Factor (LOF)) 감소 방법을 사용
3. 가장 높은 이상치 점수를 가진 상위 τ%의 패치가 제거됨
- 코어셋은 노이즈 제거 후 남은 패치의 하위 집합
4.다른 방법과는 달리, 해당 메모리 뱅크는 코어셋의 샘플과 그들의 이상치 점수로 구성되어 있으며, 이들은 소프트 가중치로 저장됨.
- 소프트 가중치는 추론에서 이상 점수를 재가중하는 데 추가로 활용
세가지 노이즈 방법 소개 : Nearest Neighbor, Multi-Variate Gaussian, Local Outlier Factor (LOF)
이미지 수준의 노이즈 제거의 목표: X에서 Xnoise를 찾는 것
- X = {xi : i ∈ [1, N], xi ∈ R^(C×H×W)}는 훈련 이미지를 나타냄 (channels C, height H, width W ),
- ϕi ∈ R^(c∗×h∗×w∗)는 이미지 xi ∈ X의 feature map ( channels c ∗ , height h ∗ , width w ∗ )을 나타냄
- xi의 (h, w) 위치에 있는 집계된 feature map 의 패치는 ϕi(h, w) ∈ R^c∗로 나타냄
1) Nearest Neighbor
- 깨끗한 샘플보다 노이즈 샘플의 양이 적은 가정 하에, 최근접 이웃 거리를 사용
- 다. 이 방법은 각 패치의 최근접 이웃 거리를 계산하고, 거리가 크면 이상값으로 간주
- 사전 훈련된 네트워크의 최소 특징 거리가 이상을 식별하는 데 유용함 but 서로 다른 클러스터 간의 불균형한 분포로 인해 문제가 발생할 수 있다. ☞ 이를 극복하기 위해, 다른 " Multi-Variate Gaussian"을 제안하여 이상치 점수를 계산합니다.
2) Multi-Variate Gaussian
- 가우시안의 정규화 효과로 모든 깨끗한 이미지의 특징을 동등하게 처리할 수 있습니다.
- 이미지 특성에 가우시안 분포를 동적으로 적용하기 위해 각 패치 ϕi(h, w)에 대한 배치 차원에서 이상치 확률을 계산함
- 다변량 가우시안 분포 N(µh,w, Σh,w)는 µh,w가 ϕi(h, w)의 배치 평균이고, 샘플 공분산 Σh,w인 것으로 정의
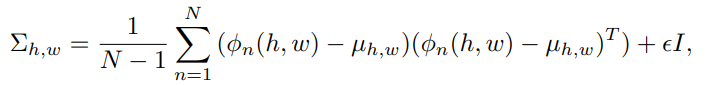
- 따라서, 이상치 점수를 계산할 때 모든 샘플을 제외하지 않기 때문에 모든 샘플이 공통 분포를 공유할 수 있으며, 이는 한 번에 계산하는 것보다 훨씬 계산 비용이 적다.
- Mahalanobis 거리는 각 패치의 노이지 크기인 Wmvgi(h, w)로 계산됨
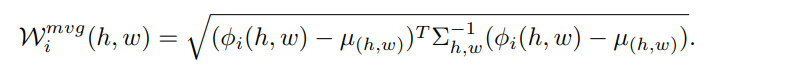
- Mahalanobis 거리가 높으면 이상치 점수가 높다.
- 가우시안 분포는 이미지 특성의 본질을 정규화하고 포착하지만, 작은 특징 클러스터는 큰 특징 클러스터에 압도당할 수 있다.
☞ 따라서 1) 모든 이미지 특성을 동등하게 처리하고, 2) 큰 클러스터와 작은 클러스터를 동등하게 처리하며, 3) 고차원 계산이 가능한 방법이 필요
☞ LOF에서 영감을 받아, 세 가지 질문을 해결함
3) Local Outlier Factor (LOF)
- LOF [44] : 주로 전자 상거래에서 범죄 활동 탐지를 위해 사용되는 지역 밀도 기반의 이상 탐지기
- 각 패치의 normalize local density를 사용하면, 대형 클러스터의 압도적 효과가 크게 줄어든다.
- normalize local density인 lrdi(h, w)를 먼저 다음과 같이 계산:
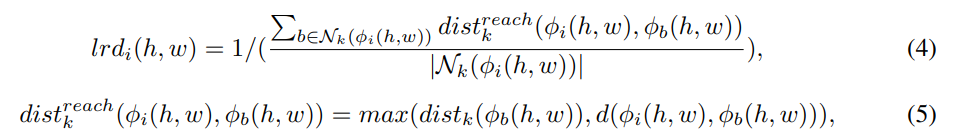
- 변수 정의)
d(ϕi(h, w), ϕb(h, w)) : L2-norm , distk(ϕi(h, w)) : k번째 neighbor의 거리 ,
Nk(ϕi(h, w)) : k-최근 이웃의 집합 , |Nk(ϕi(h, w))|: 반복된 이웃이 없을 때 일반적으로 k와 같은 집합의 수 - 모든 클러스터를 동등하게 처리하기 위해 지역 밀도를 상대적 밀도로 정규화하려면 아래와 같이 이미지 i의 상대 밀도 WLOF i (h, w)를 정의:
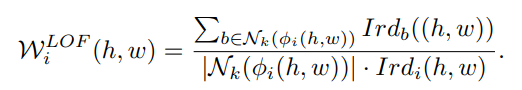
- (h, w)는 패치 자체의 이웃에 대한 이웃의 상대적 밀도를 나타내며, 이는 패치의 'inlier confidence'으로 표시됨
- LOF가 가장 우수한 성능을 제공
- 그러나, 정리된 훈련 세트를 시각화 한 후, 일부 경직 된 노이즈 샘플이 여전히 데이터 세트에 숨어있는 것을 발견함 ☞ 노이즈 데이터의 영향을 더 완화하기 위해, 이상 점수에 따라 노이즈 샘플의 가중치를 다운 조정하는 소프트 재가중 방법을 제안
Anomaly Detection based on SoftPatch : 소프트 재가중 방법
- SoftPatch 기반의 이상 탐지는 Coreset의 구성 외에도, 모든 선택된 패치의 이상 요인이 메모리 은행에 소프트 가중치로 저장함
- 메모리 은행을 사용하여 테스트 이미지의 각 패치에 대해 가장 가까운 이웃을 찾아 이상 점수를 계산
- 이상 점수는 패치 수준에서 계산되고, 가장 높은 점수를 이미지 수준의 이상 점수로 채택함
- 이를 통해 이상을 탐지하고, 결과를 평가하여 성능을 확인할 수 있다.
평가 결과 분석
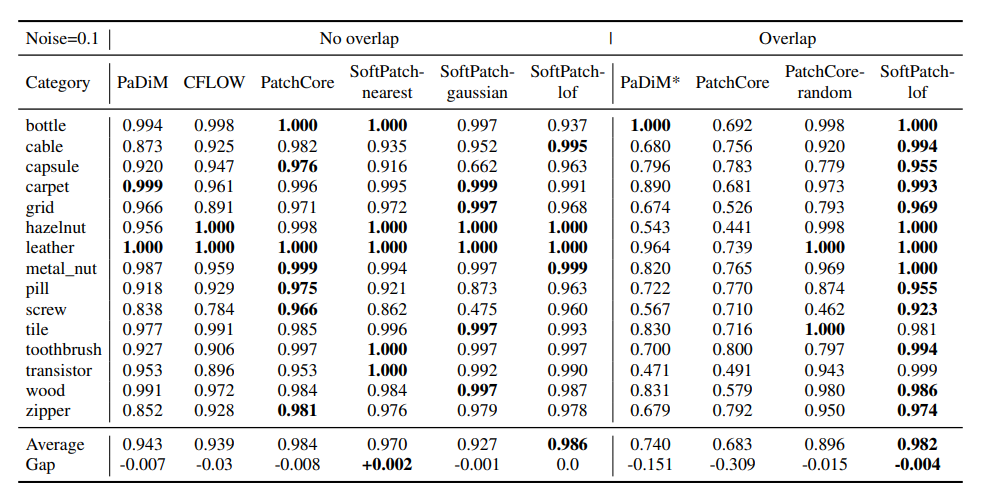
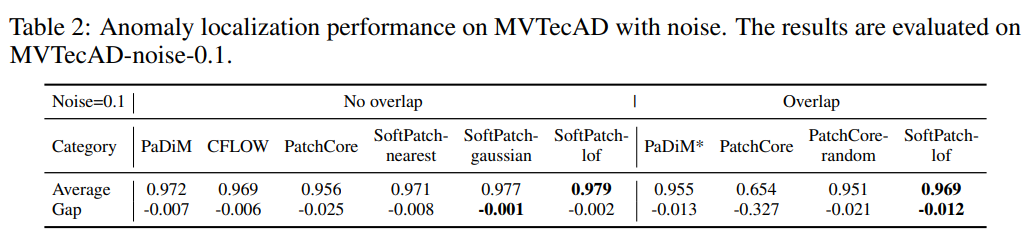
* 결과 보는 방법:
- Overlap은 삽입된 이상 이미지가 테스트 세트에 포함되어 있는지를 나타냅니다.
- PaDiM*는 ResNet18를 백본으로 사용합니다.
- PatchCore-random은 기본 탐욕적 샘플러 대신 1%의 무작위 샘플러를 사용합니다.
- 갭 행은 노이즈가 있는 장면과 정상 장면 간의 성능 차이를 보여줍니다.
1: MVTecAD 데이터셋에서 노이즈와 함께 이상 탐지 성능 평가
2: ( MVTecAD 데이터셋에서 노이즈와 함께 ) 이상 위치 지정 성능
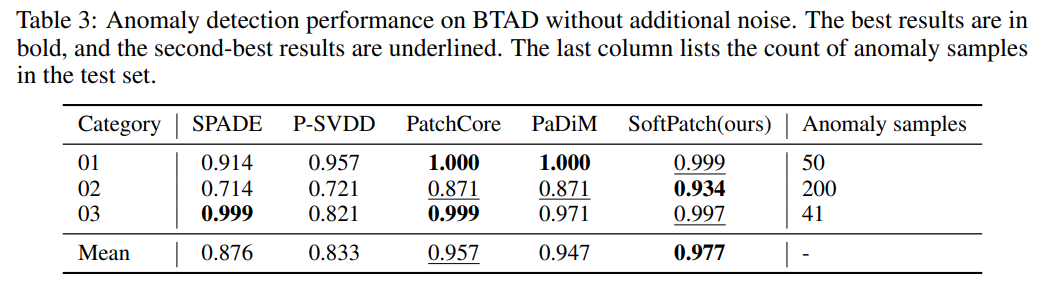
3: 추가 노이즈 없이 이상 탐지한 결과
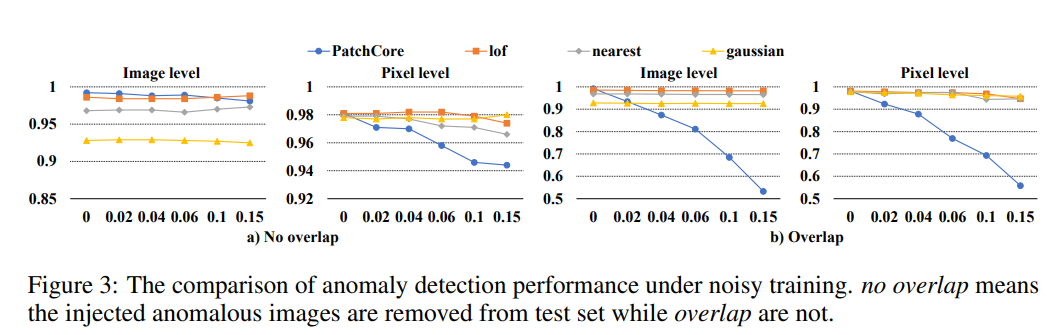
4: (노이즈가 있는 환경에서) 이상 탐지한 성능 비교
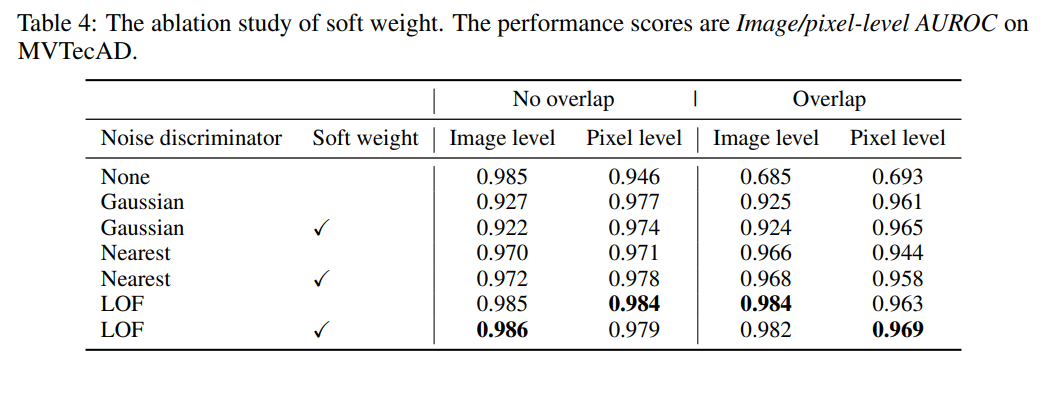
5: 소프트 가중치의 제거 연구
- 성능 점수는 MVTecAD의 이미지/픽셀 수준 AUROC
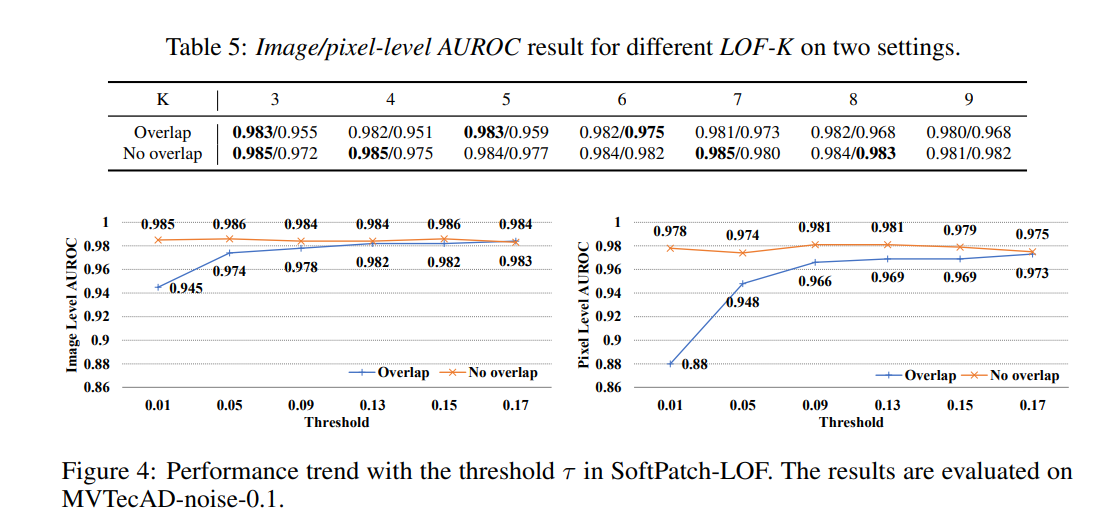
6: 두 가지 설정에서 LOF-K에 따른 이미지/픽셀 수준 AUROC 결과 & SoftPatch-LOF에서 임계값 τ에 따른 성능 추이
논문의 기여점
• 잡음이 있는 데이터를 이용한 이미지 감각 이상 탐지에 초점을 맞춘 첫 번째 연구
• 코어셋 메모리 뱅크를 위한 패치 수준의 노이즈 제거 전략을 제안
- 기존의 샘플 수준 노이즈 제거에 비해 데이터 사용률을 실질적으로 향상시킴
• 추가적인 노이즈 데이터가 있는 환경 및 노이즈가 없는 일반 환경에서 잘 작동하는 Unsupervised AD의 기준을 설정함
• 성능적인 측면: PatchCore와 유사한 효과를 달성하며, 더 많은 노이즈 강건성과 더 적은 검색을 통해 가능