Xie, Guoyang, et al. "Im-iad: Industrial image anomaly detection benchmark in manufacturing." IEEE Transactions on Cybernetics (2024).
https://paperswithcode.com/paper/im-iad-industrial-image-anomaly-detection
Papers with Code - IM-IAD: Industrial Image Anomaly Detection Benchmark in Manufacturing
Implemented in 2 code libraries.
paperswithcode.com
Abstract
Image anomaly detection (IAD) is an emerging and vital computer vision task in industrial manufacturing (IM). Recently, many advanced algorithms have been reported, but their performance deviates considerably with various IM settings. We realize that the lack of a uniform IM benchmark is hindering the development and usage of IAD methods in realworld applications. In addition, it is difficult for researchers to analyze IAD algorithms without a uniform benchmark. To solve this problem, we propose a uniform IM benchmark, for the first time, to assess how well these algorithms perform, which includes various levels of supervision (unsupervised versus fully supervised), learning paradigms (few-shot, continual and noisy label), and efficiency (memory usage and inference speed). Then, we construct a comprehensive image anomaly detection benchmark (IM-IAD), which includes 19 algorithms on seven major datasets with a uniform setting. Extensive experiments (17,017 total) on IM-IAD provide in-depth insights into IAD algorithm redesign or selection. Moreover, the proposed IM-IAD benchmark challenges existing algorithms and suggests future research directions. For reproducibility and accessibility, the source code is uploaded to the website: https://github.com/M3LAB/open-iad
본 페이지에서는 해당 연구를 이해의 편의를 위해서 배경, 제안모델 요약, 선행연구, 제안모델과 실험방법, 평가 결과 분석, 논문의 기여점 순으로 정리합니다. 개인적인 분석이므로, 해당 논문에 대한 평가가 아닌 '해당 논문이 어떠한 내용이다'를 정리한 논문 리뷰로서 참고하고 봐주시면 감사하겠습니다. 더욱 자세한 내용을 위해서는 첨부된 논문을 읽어주세요:) 또한, 해당 모델의 코드가 논문에 첨부되어 있으니 참고하실 분은 참고바랍니다.
특히, 해당 모델의 코드가 공개되어 있습니다. IM-IAD의 소스 코드는 웹사이트 https://github.com/M-3LAB/IM-IAD에 업로드되었습니다. 확인하시고 싶으신 분들을 Github 링크 들어가서 확인해주시면 될 것 같습니다.
*선행연구의 논문이 보고 싶다면, 본 논문의 references에서 확인 부탁드립니다:)
언제든 피드백은 환영입니다:)
배경
- 이미지 이상 탐지(Image Anomaly Detection, IAD)에 대한 많은 고급 알고리즘이 보도되었지만,
실제 산업 제조에서는 몇 가지 IAD 알고리즘만 사용되고 있으며, 학술 연구와 실제 응용 사이의 간극이 존재한다.
- 그럼에도 불구하고, 산업의 요구 사항을 분석하는 데는 거의 노력이 기울이지 않고 있다.
- "continual IAD, few-shot IAD, noisy label IAD, 정확성 및 효율성 간의 균형" 등 현실적인 IM 요구사항이 지켜지지 x
[ continual IAD ]
*Catastrophic forgetting로 인해 지속적인 학습 능력 x
( *카타스트로피 희망 (Catastrophic forgetting)은 기계 학습의 분야에서 발생하는 현상 중 하나로, 신경망 모델이 새로운 데이터를 학습할 때 이전에 학습한 정보를 완전히 잊어버리는 현상을 의미 )
[ few-shot IAD ]
상업적 보안성으로 인해 많은 정상 데이터 샘플을 수집하기 어렵다
→ 학습하기 위한 충분한 데이터 샘플 x
[ noisy label IAD ]
Nosiy labeling issue를 고려하지 않아서 작은 사이즈의 결함 탐지 불가
→ 잘못 탐지할 가능성 o
[ 정확성 및 효율성 간의 균형 ]
IAD 알고리즘의 정확도를 높이는데 집중하는 대신 속도 및 GPU 메모리 사이즈를 고려 x
→ 산업에서 사용 불가능
☞ So, 산업 제조(Image Manufacturing)을 위한 균일한 벤치마크를 구축하는 것이 중요하고 긴급하다.
제안 모델 요약
해당 논문에서 제안하는 IM-IAD는 연구와 산업 제조 과정의 요구 사항을 분석하고, 완전 지도 학습을 위한 IAD 알고리즘의 "부분 레이블의 중요성", "잡음 설정에서의 잡음 비율의 영향", "지속적 학습을 위한 설계 원칙" 및 "논리적 이상에 대한 전역적 특징의 중요한 역할"에 대한 심층적인 통찰력을 제공하고 산업 IAD에 대한 미래 방향을 제안한다.
선행연구 요약
*해당 부분에서 각 선행연구를 깊게 다루기보다는 어떠한 선행연구 모델들이 있었고, 논문에서 이야기하는 Insight 위주로 정리되었습니다

- Unsupervised IAD :
Unsupervised IAD 에는 1) 특징 임베딩 기반 방법과 2) 재구성 기반 방법이 존재
1) 특징 임베딩 기반 접근법은 teacher-student, normalizing flow, memory bank, one-class classification 네 가지 범주로 나뉜다. 가장 전형적인 방법은 teacher-student 모델과 memory bank 기반 모델이지만, 이러한 방법들은 선생 네트워크의 성능이나 메모리 은행의 크기에 많이 의존하기 때문에 실제 산업 분야에서의 일반화 능력을 제한할 수 있다.
2) 재구성 기반 방법은 오토인코더, 생성적 적대 신경망, 트랜스포머, 확산 모델과 같은 방법이 사용되어 왔다. 이러한 방법들은 상당한 양의 훈련 시간을 요구하지만 특성 임베딩 기반 방법에 비해 성능이 아직 부족하여 실제 산업 생산의 요구를 충족시키는 것이 어려운 상황이다.
이러한 방법들은 대부분 성능이 좋지 않고, 실제 산업 제조에 적합하지 않을 수 있다. - Unsupervised IAD
Unsupervised IAD와 달리, Fully supervised IAD 방법은 이상 샘플을 훈련에 사용한다. 그러나 몇몇 방법은 비지도( Unsupervised ) 방법보다 이상점을 식별하는 데 불리하다. 비정상 샘플 데이터 활용에 대한 개선 가능성이 여전히 많이 남아 있다. - Few-shot IAD :
Few-shot IAD는 데이터의 수요를 크게 줄일 수 있는 매우 유망한 분야이다.
- GraphCore [84]는 퓨-샷 작업을 위한 효율적인 시각 등위 불변 특징을 설계하여 빠른 훈련을 수행하고 소수의 샘플을 사용하여 이상점을 구별하는 능력을 크게 향상시킴.
- FastRecon [29]은 정상 샘플의 특징을 저장하여 추론 과정에서 이미지 재구성을 지원하므로, 퓨-샷 학습 시나리오에서 재구성 네트워크를 훈련 할 수 있음.
- WinCLIP [38]은 특징 비교 접근 방식을 제로-샷 시나리오로 확장함.
- CLIP [64]을 사용하여 정상 또는 비정상 설명의 텍스트 특징을 추출하고, 이를 테스트 이미지 특징과 비교하여 이상 감지를 수행. [논문 리뷰] Learning Transferable Visual Models From Natural Language Supervision (tistory.com)
- Cao 등 [8]은 기초 모델의 다양한 다중 모달 사전 지식(예: Segment Anything [44])을 활용하여 제로-샷 설정에서 여러 벤치마크에서 비슷한 성능을 달성. [논문리뷰] Segment Any Anomaly without Training viaHybrid Prompt Regularization (tistory.com)
- AnoVL [25] 및 AnomalyGPT [31]는 시각 언어 모델의 이해 능력을 활용하여 제로-샷 시나리오에서 새로운 최첨단 결과를 달성했지만, 이러한 모델의 크기는 실제 생산 라인에 배치하기에 너무 크다는 단점을 지님.
산업 현장의 실제 필요성으로 인해, 퓨-샷 학습은 이상 감지에서 미래의 연구 중점 사항으로 남아 있습니다. - Noisy IAD :
IAD 분야에서는 실무에서 불가피하게 발생하는 노이즈 데이터 학습이 문제가 되며, 이를 해결하기 위한 노력이 필요하다.
- SoftPatch [41]는 비지도 학습 방식으로 패치 수준에서 효과적으로 데이터를 소음 제거함 [논문리뷰] SoftPatch: Unsupervised Anomaly Detection withNoisy Data (tistory.com)
- InReaCh [58]은 이미지 내부 관계를 학습하여 모델의 표현 능력을 강화함. 인공적으로 오염된 데이터로 훈련되어도 최첨단 결과에 근접할 수 있음. - Continual IAD :
지속적 학습을 통합한 작업은 이상 감지의 발전과 함께 증가하고 있으며, 더 많은 탐구가 필요하다.
- 산업용 IAD를 위한 첫 번째 CL 벤치마크는 Li 등 [51]에 의해 소개되었지만, 그들의 설정은 서로 다른 데이터셋 간의 큰 도메인 갭을 무시함
- LeMO [30]은 클래스 내 지속적 학습 문제에 초점을 맞추지만, 클래스 간 망각 문제를 간과함
이러한 방법들은 실제 산업적 응용에 사용될 수 있는 IAD 알고리즘의 미래 방향을 보여준다.
제안모델과 실험방법
1) 문제정의:
IAD의 목표는 대상 범주에서 정상 또는 비정상 샘플이 주어졌을 때, 이상 감지 모델이 이미지가 이상 여부를 예측하고, 예측 결과가 이상일 경우에는 이상 부위를 지역화하는 것이다. 본 논문에서는 각 Unsupervised IAD, Fully supervised IAD, Few-shot IAD, Noisy IAD, Continual IAD를 설정한다.
Unsupervised IAD:
Training set는 각 카테고리별로 오직 m개의 정상 데이터 샘플로 구성
Test set는 정상과 비정상 데이터 샘플 모두 포함
Fully supervised IAD:
Training set는 m개의 정상 데이터와 n개의 비정상 데이터로 구성( n ≪ m)
해당 실험의 경우 n=10으로 설정함.
Few-shot IAD:
특정 카테고리에서 m개의 정상 샘플로만 구성된 훈련 세트가 주어진다.
여기서 m은 8 이하의 값이며, 대상 카테고리에 대해 m은 각각 1, 2, 4, 8이 될 수 있다.
Noisy IAD:
Training set는 m개의 정상 데이터와 n개의 비정상 데이터로 구성(n <= (m+n)*0.2)되며, n개의 비정상 샘플은 정상 샘플로 레이블이 지정되어 있다.
Continual IAD:
Training set 는 T total train은 n개의 카테고리로 구성되어 있습니다. T total train = T 1 train, T 2 train, ..., T n train로 나타낼 수 있으며, 이는 T total train = Σᵢ₌₁ⁿ Tᵢ train과 같다. 여기서 각 하위 집합 Tᵢ train은 특정 카테고리 ci의 정상 샘플로 구성되어 있다. IAD 알고리즘은 CL 시나리오에서 각 카테고리 데이터 세트 Tᵢ train에 대해 한 번 훈련됩니다. 테스트 중에는 업데이트된 모델이 이전 데이터 세트 T total test의 각 카테고리에 대해 평가된다. 즉, T total test = T 1 test, T 2 test, ..., T i−1 test로 표시된다.
2) 제안 모델:
산업 제조 기반 IAD 벤치마크로, 19가지 알고리즘, 7개의 데이터셋 및 5가지(Unsupervised IAD, Fully supervised IAD, Few-shot IAD, Noisy IAD, Continual IAD) 설정을 포함하여 Uniform한 벤치마크를 구축
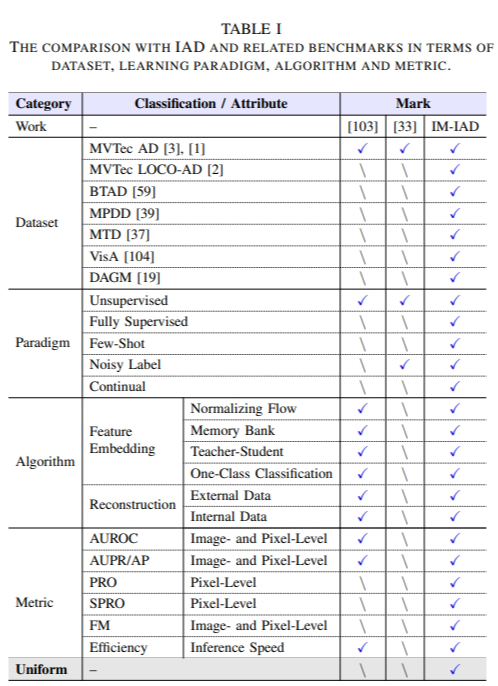
3) 기준 방법:
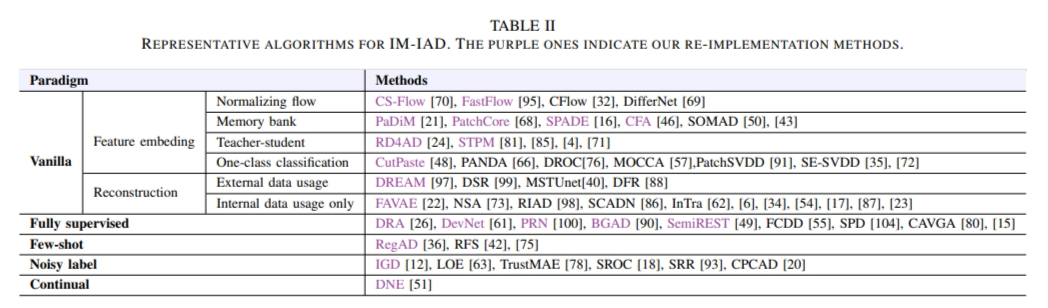
IM-IAD에 구현할 알고리즘의 기준 제시 - IM-IAD는 "알고리즘이 완전히 지도된 및 비지도 지도 수준", "잡음 내성 능력", "데이터 효율적 적응 (퓨-샷"), 그리고 "재앙적인 망각을 극복할 수 있는 능력"과 같은 측면에서 대표적이어야 한다.
4) 데이터셋:
본 연구의 IM-IAD에서는 MVTec AD, MVTec LOCO-AD, MPDD, BTAD, VisA, MTD 및 DAGM을 포함한 7개의 공개 데이터셋을 사용하여 포괄적인 연구를 수행했다.

=> DAGM은 합성 데이터셋이고, MVTec LOCO-AD는 논리적 IAD를 제안하며, VisA는 다중 인스턴스 IAD를 제안한다.
5) 평가 지표:
1. AU-ROC/AUC : 구조적 이상에 대하여 평가
2. 정밀도-재현율의 영역 아래 (AUPR/AP) 및 PRO: 이상 위치 지정의 능력을 평가
3. sPRO : 논리적 이상에 대해서 사용하여 논리적 결함 감지 능력을 측정
4. Forgetting Measure (FM) : 재앙적 망각에 대한 저항 능력을 평가

6) 하이퍼파라미터:

평가 결과 분석
*해당 부분에서는 결과들을 다 가져올 수 없어서, 각 실험에 대한 전반적인 분석 결과를 작성하였습니다. 더 보고 싶으신 부분은 해당 논문 들어가셔서 결과 보시면 좋을 것 같습니다.
- Overall Comparisons (전체 비교):
- 다양한 데이터셋에 대한 평가를 통해 특정 알고리즘의 우세성은 데이터셋에 따라 다르며, PatchCore 등의 최신 방법들도 모든 측면에서 우수하지 않음을 확인.
- 이미지 수준 및 픽셀 수준 평가 지표는 서로 다른 능력을 나타내며, 이 두 가지 지표 모두 중요하다는 점을 강조.
- Role of Global Features in Logical IAD (논리적 IAD에서 전역 특징의 역할):
- GCAD와 같은 전역 특징을 활용한 방법이 일반적인 IAD 방법보다 우수한 성능을 보임.
- Transformer 및 Normalizing Flow와 같은 최신 아키텍처가 논리적 이상 탐지에서 잠재력을 보이며, RD4AD와 같은 병목 구조도 유효.
- Abnormal Data for Fully Supervised IAD (완전 감독형 IAD의 비정상 데이터):
- 완전 감독형 방법은 비정상 훈련 샘플을 사용하여 정상 및 비정상 샘플 간의 차이를 활용하여 이상을 예측.
- 하지만 비정상 샘플 수집 및 레이블링에는 높은 비용이 따르며, 더 효율적인 알고리즘이 필요.
- Rotation Augmentation for Feature-Embedding based Few-Shot IAD (특징 임베딩 기반 피쳐샷 IAD의 회전 보강):
- 회전은 적은 데이터에서 IAD 성능을 향상시키는 효과적인 데이터 증강 방법.
- 비정상 샘플의 합성은 중요하지만 어려움.
- Importance Re-weighting for Noisy IAD (잡음이 있는 IAD의 중요도 재가중):
- 특징 임베딩 기반 방법이 잡음이 있는 상황에서 효과적.
- 샘플 선택은 IAD의 견고성 향상에 중요한 역할을 함.
- Memory Bank-based Methods for Continual IAD (연속 IAD를 위한 메모리 은행 기반 방법):
- 메모리 은행 기반 방법은 지속적인 IAD에서 유용하며, 메모리 크기 및 이전 작업과의 간섭을 최소화해야 함.
- 실제 산업 환경에서의 배치 및 메모리 용량 관리가 중요한 문제.
- Uniform View on IM-IAD (IM-IAD에서의 일관된 시각):
- 다양한 측면에서 효과적인 IAD 알고리즘의 필요성을 강조하며, 실제 환경에서의 적용 가능성과 관련된 다양한 도전 과제를 제시.
☞각 방법은 특정한 상황에서 강점을 가지며, 실제 응용 프로그램에 적합한 방법을 선택하는 데 고려해야 할 다양한 요소가 있다.
논문의 기여점
• 제조 공정에서 과학적 문제를 추출하고 이미지 이상 탐지의 학술 연구와 산업 실천 사이의 간극을 메우기 위한 표준화된 균일한 벤치마크를 제시한다.