오늘은 노이즈 주는 방법을 가져와봤습니다.
노이즈 기법은 데이터를 확장 및 증강할 때 자주 사용합니다. 데이터의 형태에 따라 노이즈 줄 수 있는 방법이 다양한데, 오늘은 텍스트형 데이터 노이즈 주는 방법과 음성 데이터 노이즈 주는 대표적인 방법을 다뤄보고자 합니다.
주로 노이즈 기법의 경우, 음성 데이터와 이미지 데이터에 자주 사용됩니다. 텍스트형 데이터에 노이즈를 경우는 많이 사용하지 않지만, 궁금해서 정리해봤습니다.
(음성 데이터에 노이즈 기법만 보고싶을 경우, 스크롤 하셔서 아래부분만 보시면 됩니다)
텍스트 형태 데이터 노이즈 주는 방법
먼저 텍스트형 데이터에 노이즈를 주는 경우에 유의할 점을 말씀드리고 기법을 설명하도록 하겠습니다.
자연어 문장의 경우 생각보다 어순 변화나 단어의 변화에 민감하기 때문에 생각처럼 잘 동작하지 않을 수 있다는 것입니다. 또한 규칙에 의해서 문장을 변형할 경우, 규칙 자체를 신경망이 학습할 수 있기 때문에 위험할 수 있습니다. 따라서 이미지만큼 쉽게 데이터를 증강할 수는 없지만, 종종 다음과 같은 방법을 통해 데이터를 증강합니다.
대표적으로 단어 생략, 단어 교환, 단어 이동하는 방법이 있습니다.
1. 단어의 생략
단어의 생략은 임의로 일정 확률로 단어를 생략하는 방식입니다.

만약 생략 확률이 너무 높다면 문장의 의미가 왜곡될 가능성이 높아지고, 생략 확률이 낮다면 단어 증강의 효과가 줄어들 수 있다는 점 유의해서 사용해야 하는 방식입니다.
2. 단어의 교환
단어의 교환은 임의로 일정 윈도우(window) 내에서 단어를 교환하는 방식입니다.
예를 들어 다음 그림과 같이 ‘학교에’라는 단어를 앞뒤 3단어까지의 범위 내에서 임의의 단어를 선택하여 교환하는 것입니다. 이를 3 윈도우 내에서 교환했다고 생각주시면 됩니다.
3. 단어의 이동:
단어의 이동은 일정 윈도우 내에서 단어를 이동하는 방식입니다.
한국어는 교착어에 속하며 어순에 제한받지 않기 때문에, 이러한 단어의 교환 및 이동 등은 한국어의 경우 훨씬 더 잘 동작할 수 있습니다. 하지만 일부 언어에서는 이에 비해 훨씬 제한적일 수 있으므로, 언어에 대한 면밀한 고찰이 수행된 이후에 데이터 증강 작업이 수행되어야 합니다.
음성 형태 데이터 노이즈 주는 방법
대표적으로 white noise, shifting, stretching, reverse, minus 5가지 기법을 다뤄보고자 합니다.
1. White Noise
White Noise는 noise 방식으로 일반적으로 쓰는 잡음 끼게 하는 것 기법입니다.
원본데이터에 비해 그래프가 두꺼워진 것을 볼 수 있습니다. 가장 흔히 쓰는 방법으로 모델의 일반화를 하는데 많이 사용됩니다.
2. Shifting
Shifting는 데이터를 roll하는 것입니다.
그림을 보시면, 원래 빨간선 쯤에서 끝났던 데이터가 새로운 지점에서 시작하게 되는 것을 볼 수 있습니다. 이처럼 데이터를 옆으로 roll해주는 것으로, 분류(classfication)할 때 추가 데이터로 도움이 됩니다.
3. Streching
Streching은 늘어지게 만드는 기법입니다.
그림으로 보면 빈공간들이 채워진 느낌이 드는것을 확인하실 수 있습니다.
4. Reverse
Reverse는 소리를 거꾸로 재생하는 기법입니다.
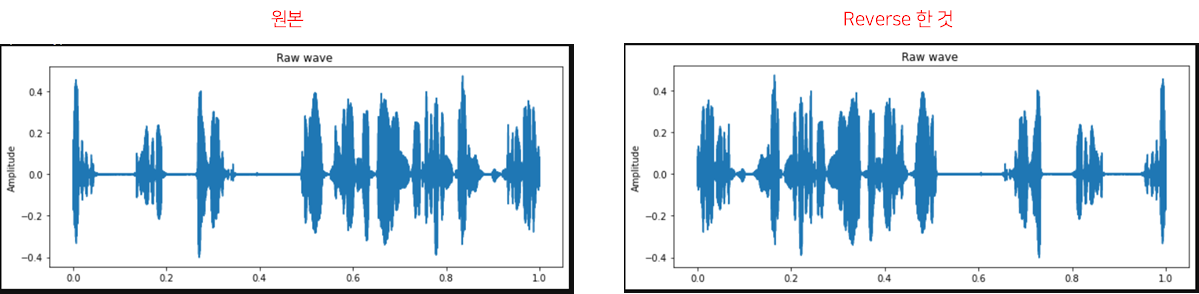
위의 그림과 같이, 원본데이터 세로축 기준으로 뒤집어 졌다고 보면 됩니다. 앞선 3가지 방법과 다른 점은 원본데이터의 변형을 가하지 않았다는 점입니다.
5. Minus
Minus는 음성데이터를 x축 기준으로 뒤집은 것입니다.
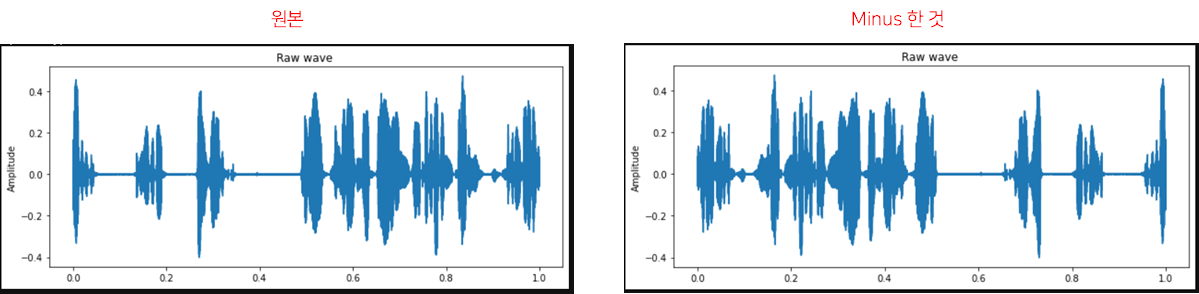
사람 귀에는 똑같이 들린다는 특징을 가지고 있으며, 원본에 변형을 가하지 않고 단순한 대칭을 사용한 기법입니다.
'데이터 분석 • 처리' 카테고리의 다른 글
| 차원 축소(Dimensionality Reduction) 개념과 Wrapper 기법 (0) | 2024.05.17 |
|---|---|
| 박스 플롯(IQR 사분위수): 이상치 찾기 (0) | 2024.03.26 |
| 데이터에 NULL이 포함되면 어떻게 처리해야할까? (결측치 처리) (2) | 2024.03.16 |
| 데이터 전처리는 무엇이고, 왜 해야할까요? (0) | 2024.03.10 |