머신러닝 학습 코드를 구현하고 시각화할때 많이 사용하고 들어본 라이브러리들에는 무엇이 있나요?
Numpy, Pandas, Sklearn,Matplotlib, Seaborn에 대해 자주 들어보셨을 것입니다.
참고로, 딥러닝 분야에서는 Tensorflow, Pytorch, Keras를 많이 사용하며,
오늘은 머신러닝을 수행할 때 유용한 라이브러리를 정리하고자합니다.
아래는 머신러닝에서 사용하는 라이브러리입니다.
| 러이브러리 | 설명 |
| 넘파이=Numpy | 다차원 배열에 대한 빠른 처리를 지원하는 라이브러리 (판다스에 비해 사람 눈에는 다소 읽기 불편하지만 메모리가 덜 들고 계산도 더 빠르다) |
| 판다스=Pandas | 넘파이 기반으로 구현한 라이브러리. 인간 친화적인 자료구조를 제공해 데이터를 넘파이보다 쉽게 읽고 변형이 가능하다 |
| 사이킷런=Sklearn | 데이터 분석과 머신러닝 관련 다양한 기능을 지원하는 강력한 라이브러리. 데이터 전처리, 모델링, 모델 평가 등 굉장히 광범위한 분야 지원 |
| 맷플롯립 = Matplotlib | 시각화 라이브러리 |
| 시본 = Seaborn | 맷플롯립 기반으로 구현한 라이브러리. 맷플롯립보다 사용이 쉽고 더 깔끔한 결과물을 보여줌 |
| 사이파이 = Scipy | 수학, 통계, 신호처리, 이미지 처리, 함수 최적화에 사용되는 강력한 데이터 과학 라이브러리 |
| 테아노 = Theano | 수학 표현식, 특히 행렬 값을 조작하고 평가하는 라이브러리 |
이 중 Theano는 학습 과정에서 저도 잘 사용해보지 않은 라이브러리입니다.
하지만, 직접 데이터가 계산되는 과정을 확인하고 싶을 때 유용할 거 같다는 생각이 드네요.
그러면 해당 라이브러리들을 직접 사용한 예시를 봐볼까요?
해당 포스팅에서는 정말 자주 사용하는 Seaborn, Pandas, Sklearn, Matplotlib 라이브러리들의 예시를 다룹니다.
- Seaborn
import seaborn as sns
penguins = sns.load_dataset("penguins")
sns.histplot(data=penguins, x="flipper_length_mm", hue="species", multiple="stack")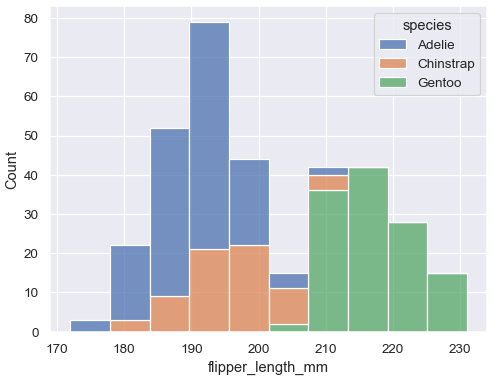
이와 같이 import하여 라이브러리를 불러오고, 히스토그램을 출력할 수 있습니다.
이외에도 Seaborn에서는 선형 그래프(lineplot), 산점도(scatterplot),히스토그램(hisplot), 박스 플롯(boxplot), 히트맵(hearmap), 막대 그래프(barplot) 등의 시각화 그래프를 제공합니다.
seaborn: statistical data visualization — seaborn 0.13.2 documentation
seaborn: statistical data visualization — seaborn 0.13.2 documentation
seaborn: statistical data visualization
seaborn.pydata.org
해당 링크에서 자세한 튜토리얼을 확인하실 수 있습니다.
- Pandas
import pandas as pd
pd.DataFrame({'A': [1, 2, 3]})
User Guide — pandas 2.2.3 documentation
User Guide — pandas 2.2.3 documentation
User Guide The User Guide covers all of pandas by topic area. Each of the subsections introduces a topic (such as “working with missing data”), and discusses how pandas approaches the problem, with many examples throughout. Users brand-new to pandas sh
pandas.pydata.org
해당 링크에서 자세한 튜토리얼을 확인하실 수 있습니다.
- Sklearn
from sklearn.model_selection import train_test_split
# 데이터 분할 (80% 훈련, 20% 테스트)
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.2, random_state=42)다음 코드는 머신러닝 개발자들이 sklearn에서 가장 많이 사용한 기능이지 않을까 싶습니다
훈련 데이터와 테스트 데이터를 나눠주는 과정에서 이처럼 Sklearn 라이브러리를 사용하면 쉽게 사용하실 수 있습니다.
scikit-learn: machine learning in Python — scikit-learn 1.6.1 documentation
scikit-learn: machine learning in Python — scikit-learn 1.6.1 documentation
Comparing, validating and choosing parameters and models. Applications: Improved accuracy via parameter tuning. Algorithms: Grid search, cross validation, metrics, and more...
scikit-learn.org
해당 링크에서 제공하는 기능과 자세한 튜토리얼을 확인하실 수 있습니다.
- Matplotlib
import matplotlib.pyplot as plt
plt.plot([1, 2, 3, 4])
plt.ylabel('some numbers')
plt.show()
plt.plot()으로 그래프를 생성하고, plt.show() 로 그래프를 출력하는 것이 가장 기본적인 형태입니다.
이때 x,y축의 label, label 출력 위치, 그래프의 모양과 색깔 등 다양한 설정을 추가할 수 있습니다.
Tutorials — Matplotlib 3.10.1 documentation
Tutorials — Matplotlib 3.10.1 documentation
matplotlib.org
해당 링크에서 자세한 튜토리얼을 확인하실 수 있습니다.
머신러닝의 대표적인 라이브러리를 다뤄봤습니다.
유익한 시간이 되었길 바래요 :)
'AI 개념 > 기계학습, 심층학습' 카테고리의 다른 글
| 데이터 전처리 - Feature Engineering (1) | 2025.03.01 |
|---|---|
| 과적합(과잉적합) 해결방법 (0) | 2024.05.22 |
| 회귀(경사하강법, 학습률, 지역최솟값, 과적합&과소적합) (0) | 2024.03.31 |
| 머신러닝 알고리즘의 성능평가: 혼동 행렬 (TP|FP|FN|TN) (0) | 2024.03.22 |
| 불확실성(Uncertainty)란 무엇일까? (0) | 2024.02.29 |